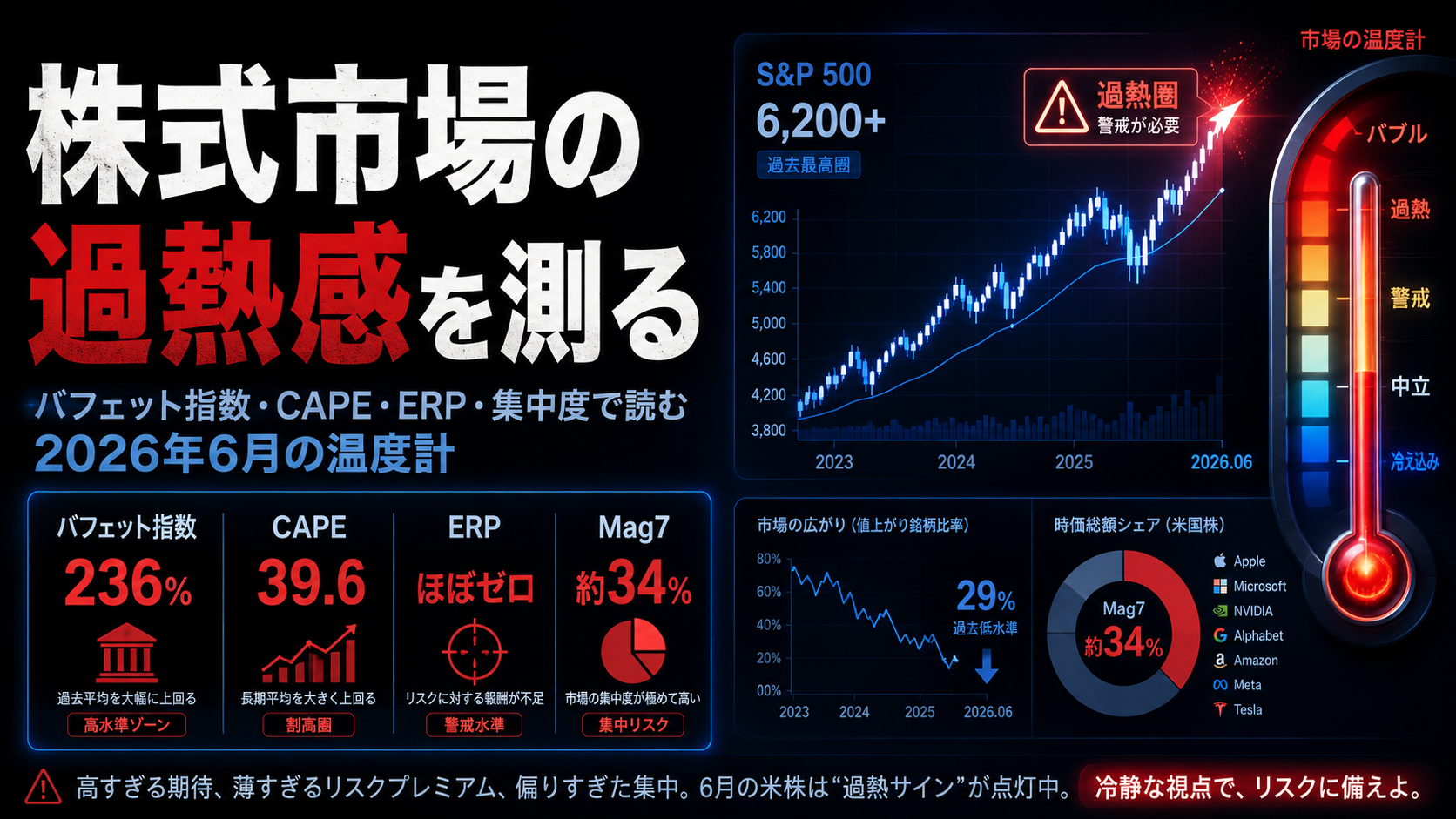
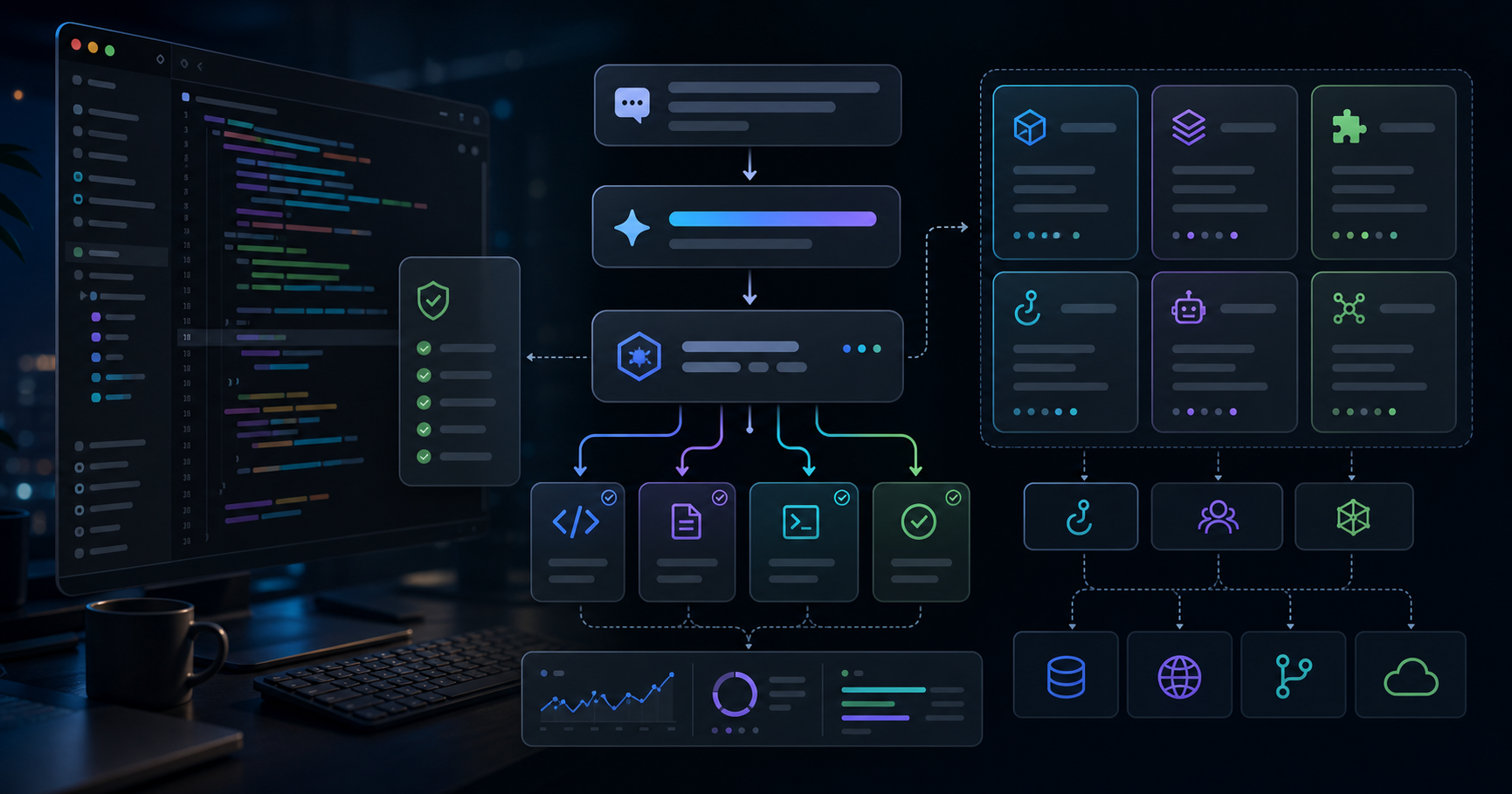
Subagentでブログリサーチを並列分業する型|投資・技術・読者ニーズを3並列で走らせ1本に統合する
前回のMCP記事で、DDメモ・ポートフォリオ・過去提案をClaude Codeに繋ぐMCPサーバーを30分で組みました。その記事の最後に「次号案:Subagentでブログリサーチを並列分業する」と書いたので、今回はそれを実際に組みます。前提として、Skill設計の記事で「Subagentは独立した調査・分担に使う」と整理した、あの役割分担をそのまま実装に落とす話です。
このブログを書くとき、私のリサーチはいつも3つに割れます。投資としてどうか・技術として何が起きているか・読者は何を知りたいか。今までは自分の頭の中で順番にやっていましたが、3軸はほぼ独立しているので、別々のsubagentに同時に走らせれば速いはずだ、と前から思っていました。今回それを型にします。投資subagentのデータ源には、前回作ったMCPサーバー(
search_dd_memos
/
fetch_doc
/
list_recent
)をそのまま再利用します。
バージョン注記: 2026年5月時点のClaude Code(Opus 4.8系)と、
.claude/agents/
によるsubagent定義の挙動を前提にしています。subagentの設定スキーマ・並列実行の挙動・CLIは変わる可能性があるので、本番運用の前に必ず公式ドキュメントとリリースノートを確認してください。
| テーマ | 学べること |
|---|
| なぜ分業 | 1本のリサーチをなぜ3軸に割ると速いのか |
| subagent定義 | 投資・技術・読者ニーズの3つの .claude/agents/*.md の書き方 |
| MCP再利用 | 投資subagentから前回のMCPツールを呼ばせる設計 |
| 並列実行 | 3つをfan-outして1本のドラフトに統合する司令役の作り方 |
| 統合 | バラバラの調査結果を矛盾なく1本に畳む手順 |
| 落とし穴 | 並列分業で実際に刺さるポイント |

最初に向き合うべきは「そもそも分ける意味があるのか」です。1本の記事のために、わざわざagentを3つ立てるのは大げさに見えます。私も最初はそう思っていました。
ただ、自分のリサーチを観察して気づいたのは、3軸が要求するソースも口調もほぼ被らないことです。投資軸はMCP越しの社内ナレッジと一次情報。技術軸は公式ドキュメント・GitHub・リリースノート。読者ニーズ軸は検索意図と過去記事の反応。これを1つのコンテキストで順番にやると、後半になるほど前半の情報が薄れていきます。長いセッションでツール結果がコンテキストを食い、肝心の執筆段階で「最初に調べたこと」が霞む、というのは誰でも経験があるはずです。
| 観点 | 直列(1セッションで順番に) | 並列(3 subagentにfan-out) |
|---|
| コンテキスト汚染 | 調査結果が全部メインに溜まる | 各subagentが自分のコンテキストで完結し、要約だけ返す |
| 速度 | 軸ごとに待つ | 3軸が同時に進む |
| 専門化 | 1つのプロンプトで全部こなす | 軸ごとにツール権限・口調・出力形式を固定できる |
| 再現性 | 毎回手順がぶれる | 定義ファイルに型が残る |
私の体感で一番効くのは、速度よりコンテキストの隔離です。subagentは独立したコンテキストで動き、メインには「要約された成果物」だけが返ってくる。だからメインのセッションは、最後の統合と執筆のために綺麗なまま保てます。ここはまだ好みが割れるところで、軽い記事なら直列で十分です。ただ、3軸とも深掘りが要る回ほど、分業の差が大きく出る、というのが現時点の私の見立てです。
実装より先に役割分担を固めます。Claude Codeでは
.claude/agents/
配下にMarkdownファイルを置くと、それがsubagent定義になります。frontmatterに
name
/
description
/
tools
、本文にシステムプロンプトを書く、という構造です。
ここで効くのは、Skill記事で書いた「descriptionは『いつ呼ぶか』を書く」がそのまま当てはまることです。subagentも、司令役がdescriptionを読んでルーティングします。だから3軸の責務が被らないように、descriptionで境界をはっきり引きます。
まず投資軸。ここだけMCPツールへのアクセスを許可します。
---
name: investment-researcher
description: >
Use to research the INVESTMENT angle of a blog topic: market size,
funded startups, valuations, prior internal DD context, and portfolio overlap.
Has access to the internal knowledge MCP server. Does NOT cover code-level
technical detail or reader/SEO intent.
tools: [search_dd_memos, fetch_doc, list_recent, WebSearch]
---
You are the investment-angle researcher for a CVC blog written by ZYL0.
Your job: given a blog topic, produce a tight investment brief.
Steps:
1. Call `list_recent(kind="memo", days=180)` to see what themes we touched recently.
2. Call `search_dd_memos(query=<topic>)` to find prior internal context.
3. For the 1-2 most relevant hits, call `fetch_doc(doc_id)` and pull only
the parts that bear on this topic. Do NOT dump full bodies.
4. Use WebSearch only for public facts (funding rounds, market sizing).
Output (Markdown, <= 400 words):
- "## Investment angle"
- 3-5 bullets: what's investable, who's funded, what we've already seen internally.
- Flag any NDA/restricted material as [internal-only] and summarize, never quote.
- End with one line: "Open question for the human:" (the judgment call we still owe).
次に技術軸。こちらはMCPには触らせず、公開情報の検証に絞ります。
---
name: tech-researcher
description: >
Use to research the TECHNICAL angle of a blog topic: how the technology
actually works, current versions, official docs, GitHub state, and a minimal
working code path. Does NOT cover investment/market or reader/SEO framing.
tools: [WebSearch, WebFetch, Read, Grep]
---
You are the technical-angle researcher for an implementation-focused blog.
Your job: verify what is TRUE and CURRENT, and find a minimal runnable path.
Steps:
1. Confirm the current version / release notes of every tool you mention.
2. Check official docs and the GitHub changelog/issues where relevant.
3. Identify ONE minimal code path the reader could actually run.
4. Note anything that recently changed or was deprecated.
Output (Markdown, <= 400 words):
- "## Technical angle"
- Version-pinned facts (no version, no claim).
- A short, copy-pasteable snippet if one is genuinely runnable.
- "Gotchas:" 2-3 bullets of things that bite in practice.
- Do NOT include uncertain API specs. If unsure, say "unverified".
最後に読者ニーズ軸。検索意図と過去記事の反応を見て、「どう書けば刺さるか」を返します。
---
name: reader-need-researcher
description: >
Use to research the READER-NEED angle of a blog topic: search intent,
what the audience is actually stuck on, framing, and title candidates.
Does NOT verify code or cover investment/market detail.
tools: [WebSearch, Read, Grep]
---
You are the reader-need researcher for a bilingual JP/EN tech blog.
Your job: figure out what the reader actually wants and how to frame it.
Steps:
1. Identify the top 3 search intents behind this topic (problem-first).
2. Grep prior posts under content/blogs/ for related coverage to avoid overlap
and to find a natural internal link.
3. Note which prior post this should link back to.
Output (Markdown, <= 300 words):
- "## Reader-need angle"
- Top 3 reader questions, ranked.
- One suggested narrative hook (the opening tension).
- 3 title candidates (JP + EN), specific and searchable.
- The internal link this post should reference.
3つとも、出力フォーマットと文字数上限を固定しているのが肝です。subagentの成果物は司令役のコンテキストに丸ごと戻るので、長すぎると統合段階で溺れます。「各軸400語以内・見出し固定」と縛るだけで、後の統合がかなり楽になります。
ここが今回の山場です。投資subagentのデータ源を、新しく作るのではなく、前回のMCP記事で作った
cvc-knowledge
サーバーにそのまま繋ぎます。MCPの良いところは、一度サーバーを立てれば、メインのセッションでもsubagentでも同じツールを共有できる点です。
プロジェクト直下の
.mcp.json
は前回のまま流用します(再掲)。
{
"mcpServers": {
"cvc-knowledge": {
"command": "uv",
"args": ["run", "python", "server.py"],
"env": {
"KB_BASE_URL": "https://kb.internal.example.com",
"KB_API_TOKEN": "${env:KB_API_TOKEN}"
}
}
}
}
投資subagentの
tools:
に
search_dd_memos
/
fetch_doc
/
list_recent
を列挙してあるので、このsubagentだけがMCPツールを使えます。技術・読者ニーズの2つには列挙していないため、社内ナレッジには触れません。
ツール権限をsubagent単位で絞れるのが、分業の地味だが大きい利点です。前回書いた「LLMから見える形に出す前に落とす」というガード方針が、subagentレベルでも効いてくれます。
投資subagentが実際に何を呼ぶかは、システムプロンプトのStepsで誘導しています。流れはこうです。
# 投資subagent内部の典型的な呼び出し順
list_recent(kind="memo", days=180)
-> 直近半年で触れたテーマ一覧(タイトル+ID)
search_dd_memos(query="drone logistics last-mile", limit=5)
-> 関連メモのID・タイトル・スニペット 上位5件
fetch_doc(doc_id="memo-2025-0417")
-> 関連する1-2本だけ本文取得(機密級はサーバー側で要約に落ちる)
ポイントは、subagent側で本文を全部取りに行かないことです。前回のツール設計(
search
で当たりをつけ、必要な1〜2本だけ
fetch_doc
)が、そのままsubagentの行動規範になります。
fetch_doc
は機密分類を見て要約だけ返すので、subagentが暴走して全文を引いても、機密はサーバー側で物理的に落ちます。
MCP側のガードが、subagentの行儀の悪さの保険になっているわけです。これは設計していて気持ちが良かった部分でした。
役割が決まったら、メインのセッションが司令役(オーケストレーター)になります。やることは2つだけ。3 subagentを並列に投げることと、返ってきた3つの成果物を1本のドラフトに畳むことです。
私が実際に使っている指示は、こういう一段のプロンプトです。Claude Codeは複数のsubagentを1ターンで並列起動できるので、明示的に「並列で」と頼みます。
あなたはこのブログのオーケストレーターです。
トピック: 「ドローン物流のラストワンマイル」
次の3つのsubagentを「並列で」起動し、それぞれの成果物を集めてください:
- investment-researcher (投資軸ブリーフ)
- tech-researcher (技術軸ブリーフ)
- reader-need-researcher (読者ニーズ軸ブリーフ)
3つが揃ったら、結果を統合して1本の記事ドラフトを書いてください。
統合ルール:
1. 読者ニーズ軸のフックを冒頭に、タイトル候補から1つ選ぶ。
2. 技術軸の version-pinned facts のみ採用。"unverified" は本文から落とす。
3. 投資軸の [internal-only] は要約のみ。原文引用は禁止。
4. 3軸で矛盾があれば本文に書かず、「未解決の論点」として最後に箇条書き。
5. 出力は content/blogs/ の bilingual テンプレ(::lang-block ja / en)に従う。
ここで効くのは、統合ルールを司令役プロンプト側に持たせることです。各subagentは「自分の軸を調べて返す」だけに集中させ、矛盾の解消や採否の判断は司令役に一本化します。subagent側に「他の軸と整合を取れ」と書くと、subagentが互いに知らない情報を勝手に補完し始めて、かえって事故ります。私は最初これをやって、技術subagentが投資の話を想像で埋め始め、危うく嘘が混ざりかけました。
統合段階のもう一つのコツは、3軸の成果物を一度そのまま並べてから書き始めることです。司令役のコンテキストに3つのブリーフが揃った状態で、初めて「どれを採用し、どれを落とすか」を判断する。いきなり書き始めると、最初に返ってきた軸に引っ張られます。地味ですが、ここで一拍置くだけで統合の質が変わる、というのが触ってみての実感です。
統合は、機械的なマージではありません。3軸は独立して走っているので、ほぼ必ず重複・温度差・矛盾が出ます。私が固定している畳み方は3ステップです。
| ステップ | やること | 判断基準 |
|---|
| 1. 採否 | 各軸の主張を「採用 / 保留 / 棄却」に仕分け | 技術軸は version 付きのみ採用。投資軸の機密は要約のみ |
| 2. 重複削除 | 同じ事実を別の軸が出していたら1回に統合 | 一次情報に近い方を残す |
| 3. 矛盾の明示 | 解決できない食い違いは隠さず「未解決の論点」に | 本文では断定せず、留保表現で書く |
特に3つ目が大事だと思っています。並列で別々に調べた結果は、たまに正面衝突します。例えば技術軸が「この規制でドローン物流はまだ商用化が難しい」と言い、投資軸が「いや、この地域では既にPoCが回っている」と言う。これを無理に1つの結論に丸めると、記事の信頼が落ちます。私はこういうとき、本文では両論併記にして、最後の「未解決の論点」に正直に残します。3軸が割れた箇所こそ、その記事で一番面白い論点であることが多い、というのが書いていての発見でした。
逆に、統合で楽をしすぎてもいけません。3つのブリーフをそのまま貼り合わせると、文体がバラバラの「3人で書いた感」が出ます。最後に司令役で一人称(ZYL0)の口調に通しで書き直す工程は、省けません。subagentは素材を集める係、司令役が一本の声で書く係、という分担が、私の中では一番落ち着いています。
仕組みはシンプルですが、運用してみると地雷がいくつかあります。私が踏んだ代表的なものを残します。
- subagentの成果物が長すぎてメインが溺れる:subagentの出力はそのまま司令役のコンテキストに戻ります。文字数上限を定義に書かないと、各軸が数千語返してきて、統合段階でコンテキストが破裂します。各軸に「300〜400語以内・見出し固定」を必ず書く。
- MCPツールが投資以外のsubagentから呼ばれる:
tools:
の列挙を忘れると、subagentがデフォルトで広い権限を持つ場合があります。機密に触れるMCPツールは、投資subagentの tools:
にだけ列挙し、他には絶対書かない。前回のサーバー側ガードがあっても、権限は二重で絞るのが安全です。 - subagentに「整合を取れ」と書いてしまう:各subagentは他軸の結果を知りません。整合や矛盾解消を頼むと、知らない情報を想像で埋め始めます。整合の判断は司令役に一本化する。
- 並列のつもりが直列になっている:「並列で」と明示しないと、1つずつ順番に走ることがあります。速度の利点が消えるので、司令役プロンプトに必ず「並列で起動」と書く。挙動はバージョンで変わり得るので、トレースで本当に同時に動いているか一度確認する。
- 投資subagentがfetch_docで全文を引きに行く:システムプロンプトで「関連する1〜2本だけ」と縛らないと、ヒット全件の本文を取りに行きます。前回のツール設計(searchで当たりをつけてからfetch)を、subagentのStepsに明文化しておく。
このあたりは公式ドキュメントには載っていない、触って初めて分かる類の話です。半年後の自分のために残しておきます。
最後に少し引いた話を。subagentを3つ立てて気づいたのは、これは自分を3人に増やす話ではなく、調査の境界線を引く話だ、ということです。
投資・技術・読者ニーズという3軸は、私の頭の中では昔から分かれていました。ただ、それを1つのセッションで順番にやると、軸がにじみ合って、どこまでが検証済みでどこからが想像か、自分でも曖昧になっていました。subagentに分けて、ツール権限と出力形式を軸ごとに固定したことで、その境界が定義ファイルとして外に出ました。判断を毎回やり直さずに済む——これはSkill記事で書いたSkillの効能と、結局は同じ話です。
そして、投資軸のデータ源に前回のMCPサーバーをそのまま再利用できたのは、設計していて一番嬉しかった点でした。MCPで一度「社内ナレッジへの蛇口」を作っておくと、それが司令役からもsubagentからも共有できる。ツールは一度作れば使い回せる、という当たり前のことが、subagentと組み合わせると効いてきます。
完璧なオーケストレーションを目指す必要はありません。まずは3つのagent定義を
.claude/agents/
に置き、次の1本で並列に走らせてみる。重ければ直列に戻せばいいだけです。机上で完璧な自動執筆パイプラインを設計するより、1本書いてみる方が、はるかに速く自分の型が見えてきます。
次号の記事案
- 案1:Subagentの成果物をHooksで検証してから統合する — 並列で返ってきた各軸のブリーフを、統合前にPostToolUse/Stop Hookで自動チェックする型。version欠落・文字数超過・internal-onlyの原文引用を機械的に弾き、司令役が綺麗な素材だけ受け取る運用を実装ベースで整理する。
- 案2:投資subagentにEU ETS・THETIS-MRVの一次データ分析をやらせる — 公開一次データ(EU ETS、THETIS-MRVフリートデータ)を投資subagentに直接分析させ、社内MCPと組み合わせて投資ブリーフの密度を上げる。データ取得・前処理・要約までをsubagent内に閉じる設計を扱う。
- 案3:オーケストレーションをSkill化して再利用する — 本記事の司令役プロンプトと3つのsubagent定義を、1つのSkillに束ねて「リサーチ並列分業」をコマンド一発で呼べるようにする。Skill・subagent・MCPの3層をどう分担させるか、実装目線で整理する。
本文の事実関係と数値前提は、再審査時にも読者が確認できる一次情報・公的資料を優先して見直しています。
本記事は情報提供を目的としたものであり、特定の銘柄、サービス、契約条件の推奨や投資助言ではありません。執筆者は記事内で触れた銘柄やサービスにポジションまたは利害関係を持つ可能性があります。調査、翻訳、校正の一部に生成AIを利用していますが、最終的な内容はZYL0が確認しています。詳細は免責事項をご確認ください。
Parallel Blog Research with Subagents: Fan Out Investment, Technical, and Reader-Need Axes, Then Merge Into One Draft
In my previous MCP post, I built a 30-minute MCP server that wires DD memos, portfolio data, and past proposals into Claude Code. I closed that post with a next-issue idea: "Parallel Blog Research with Subagents." So this time I actually build it. The premise comes straight from my Skill design post, where I argued that subagents are for isolated, parallel investigation — this is that role taken down to an implementation.
Whenever I write for this blog, my research splits three ways every single time: is it investable, what is actually happening technically, and what does the reader want to know. I used to do all three sequentially in my own head. But the three axes are nearly independent, so running them as separate subagents in parallel ought to be faster. This post turns that into a reusable pattern. For the investment subagent's data source, I reuse the MCP server from last time as-is (
search_dd_memos
/
fetch_doc
/
list_recent
).
Version note: This is based on Claude Code (Opus 4.8 line) and subagent definitions via
.claude/agents/
as of May 2026. The subagent config schema, parallel-execution behavior, and CLI can change, so always check the official docs and release notes before relying on this in production.
| Topic | What you'll learn |
|---|
| Why split | Why splitting one post's research into 3 axes is faster |
| Subagent definitions | How to write the three .claude/agents/*.md files |
| MCP reuse | Wiring last post's MCP tools into the investment subagent |
| Parallel run | An orchestrator that fans out 3 agents and merges into one draft |
| Merging | How to fold disparate findings into one consistent article |
| Gotchas | What actually bites you in parallel research |
The first thing to answer is whether splitting is even worth it. Standing up three agents for a single article looks like overkill. I thought so too at first.
But watching my own process, I noticed the three axes barely overlap — not in sources, not in tone. The investment axis pulls from internal knowledge over MCP plus public primary sources. The technical axis pulls from official docs, GitHub, and release notes. The reader-need axis pulls from search intent and how prior posts landed. Doing all three sequentially in one context means the early findings fade as you go. By the time you actually write, the tool results from step one have been crowded out of context. Anyone who has run a long session knows that feeling.
| Aspect | Sequential (one session, in order) | Parallel (fan out to 3 subagents) |
|---|
| Context pollution | All findings pile into the main context | Each subagent finishes in its own context and returns a summary |
| Speed | You wait per axis | All three advance at once |
| Specialization | One prompt does everything | Per-axis tool scopes, tone, and output format are fixed |
| Reproducibility | The procedure drifts each time | The pattern lives in definition files |
For me, the biggest win is not speed — it is context isolation. A subagent runs in its own context and returns only a summarized deliverable to the main session. That keeps the main session clean for the final merge and writing. This is still a matter of taste; for a light post, sequential is plenty. But the heavier the post — where all three axes need real depth — the more the split pays off. That, at this point, is how I read it.
Settle the division of labor before touching implementation. In Claude Code, a Markdown file under
.claude/agents/
becomes a subagent definition:
name
/
description
/
tools
in frontmatter, and the system prompt in the body.
What helps here is exactly what I wrote in the Skill post: "the description should say when to call, not what it does." The orchestrator routes by reading each subagent's description. So I draw the boundaries sharply in the descriptions to keep the three responsibilities from colliding.
First, the investment axis. Only this one gets access to the MCP tools.
---
name: investment-researcher
description: >
Use to research the INVESTMENT angle of a blog topic: market size,
funded startups, valuations, prior internal DD context, and portfolio overlap.
Has access to the internal knowledge MCP server. Does NOT cover code-level
technical detail or reader/SEO intent.
tools: [search_dd_memos, fetch_doc, list_recent, WebSearch]
---
You are the investment-angle researcher for a CVC blog written by ZYL0.
Your job: given a blog topic, produce a tight investment brief.
Steps:
1. Call `list_recent(kind="memo", days=180)` to see what themes we touched recently.
2. Call `search_dd_memos(query=<topic>)` to find prior internal context.
3. For the 1-2 most relevant hits, call `fetch_doc(doc_id)` and pull only
the parts that bear on this topic. Do NOT dump full bodies.
4. Use WebSearch only for public facts (funding rounds, market sizing).
Output (Markdown, <= 400 words):
- "## Investment angle"
- 3-5 bullets: what's investable, who's funded, what we've already seen internally.
- Flag any NDA/restricted material as [internal-only] and summarize, never quote.
- End with one line: "Open question for the human:" (the judgment call we still owe).
Next, the technical axis. No MCP access here — keep it to verifying public facts.
---
name: tech-researcher
description: >
Use to research the TECHNICAL angle of a blog topic: how the technology
actually works, current versions, official docs, GitHub state, and a minimal
working code path. Does NOT cover investment/market or reader/SEO framing.
tools: [WebSearch, WebFetch, Read, Grep]
---
You are the technical-angle researcher for an implementation-focused blog.
Your job: verify what is TRUE and CURRENT, and find a minimal runnable path.
Steps:
1. Confirm the current version / release notes of every tool you mention.
2. Check official docs and the GitHub changelog/issues where relevant.
3. Identify ONE minimal code path the reader could actually run.
4. Note anything that recently changed or was deprecated.
Output (Markdown, <= 400 words):
- "## Technical angle"
- Version-pinned facts (no version, no claim).
- A short, copy-pasteable snippet if one is genuinely runnable.
- "Gotchas:" 2-3 bullets of things that bite in practice.
- Do NOT include uncertain API specs. If unsure, say "unverified".
Finally, the reader-need axis. It reads search intent and prior-post reception, and returns "how to frame this so it lands."
---
name: reader-need-researcher
description: >
Use to research the READER-NEED angle of a blog topic: search intent,
what the audience is actually stuck on, framing, and title candidates.
Does NOT verify code or cover investment/market detail.
tools: [WebSearch, Read, Grep]
---
You are the reader-need researcher for a bilingual JP/EN tech blog.
Your job: figure out what the reader actually wants and how to frame it.
Steps:
1. Identify the top 3 search intents behind this topic (problem-first).
2. Grep prior posts under content/blogs/ for related coverage to avoid overlap
and to find a natural internal link.
3. Note which prior post this should link back to.
Output (Markdown, <= 300 words):
- "## Reader-need angle"
- Top 3 reader questions, ranked.
- One suggested narrative hook (the opening tension).
- 3 title candidates (JP + EN), specific and searchable.
- The internal link this post should reference.
The key in all three is fixing the output format and a word ceiling. A subagent's deliverable returns wholesale into the orchestrator's context, so anything too long drowns the merge step. Just constraining each axis to "≤ 400 words, fixed headings" makes the later merge far easier.
This is the centerpiece. Instead of building a new data source, I point the investment subagent at the
cvc-knowledge
server I built in
my previous MCP post. The nice thing about MCP is that once the server is up, the same tools are shared by both the main session and the subagents.
The project-root
.mcp.json
is reused verbatim from last time (repeated here).
{
"mcpServers": {
"cvc-knowledge": {
"command": "uv",
"args": ["run", "python", "server.py"],
"env": {
"KB_BASE_URL": "https://kb.internal.example.com",
"KB_API_TOKEN": "${env:KB_API_TOKEN}"
}
}
}
}
Because the investment subagent lists
search_dd_memos
/
fetch_doc
/
list_recent
in its
tools:
, only that subagent can use the MCP tools. The technical and reader-need agents do not list them, so they never touch internal knowledge.
Scoping tool access per subagent is an unflashy but large benefit of splitting. The guard model from last post — "drop data before it reaches a form the LLM can see" — keeps working at the subagent level.
What the investment subagent actually calls is steered by the Steps in its system prompt. The flow looks like this.
# Typical call order inside the investment subagent
list_recent(kind="memo", days=180)
-> recent themes over the last six months (titles + IDs)
search_dd_memos(query="drone logistics last-mile", limit=5)
-> top 5 related memos: IDs, titles, snippets
fetch_doc(doc_id="memo-2025-0417")
-> body of just the 1-2 relevant ones (restricted docs collapse to a server-side summary)
The point is that the subagent does not fetch every body. The tool design from last time — search to triangulate, then fetch only the one or two you need — becomes the subagent's behavior contract directly. Since
fetch_doc
inspects classification and returns only a summary for restricted docs, even if the subagent goes rogue and tries to pull everything, the sensitive material is physically dropped server-side.
The MCP-side guard is the insurance policy against a misbehaving subagent. That was a satisfying part to design.
Once the roles are set, the main session becomes the orchestrator. It does only two things: dispatch the three subagents in parallel, and fold the three returned deliverables into one draft.
The instruction I actually use is a single prompt like this. Claude Code can launch multiple subagents in parallel in one turn, so I ask for it explicitly.
You are the orchestrator for this blog.
Topic: "Last-mile delivery in drone logistics"
Launch these three subagents IN PARALLEL and collect each deliverable:
- investment-researcher (investment-angle brief)
- tech-researcher (technical-angle brief)
- reader-need-researcher (reader-need-angle brief)
Once all three return, merge them into one article draft.
Merge rules:
1. Open with the reader-need hook; pick one of the title candidates.
2. Use only the technical axis's version-pinned facts. Drop anything "unverified".
3. Summarize the investment axis's [internal-only] items only. Never quote source text.
4. If the three axes conflict, do NOT assert in the body; list it under "Open questions" at the end.
5. Output to the bilingual content/blogs/ template (::lang-block ja / en).
What matters here is keeping the merge rules on the orchestrator side. Each subagent stays focused on "research my axis and return"; conflict resolution and accept/reject judgment are centralized in the orchestrator. If you instead tell the subagents to "stay consistent with the other axes," they start inventing information they cannot actually see, which causes more accidents, not fewer. I did exactly this at first — the tech subagent began filling in investment claims from imagination, and a falsehood nearly slipped through.
Another merge-stage trick: lay all three deliverables out side by side before you start writing. With all three briefs present in the orchestrator's context, only then decide what to adopt and what to drop. Start writing immediately and you get dragged toward whichever axis returned first. Unflashy, but pausing one beat here changes the merge quality. That is my hands-on takeaway.
Merging is not a mechanical join. The three axes ran independently, so you almost always get overlap, tonal mismatch, and contradictions. The fold I have settled on is three steps.
| Step | What you do | Decision rule |
|---|
| 1. Accept/reject | Sort each axis's claims into accept / hold / reject | Technical axis: only version-pinned claims. Investment confidential: summary only |
| 2. De-duplicate | If two axes surfaced the same fact, merge into one | Keep the one closest to a primary source |
| 3. Surface conflicts | Don't hide unresolved disagreements — put them under "Open questions" | Don't assert in the body; hedge |
The third step matters most. Findings researched independently in parallel sometimes collide head-on. Say the technical axis claims "this regulation makes drone logistics hard to commercialize," while the investment axis says "actually, PoCs are already running in this region." Forcing those into a single conclusion erodes the article's credibility. When that happens, I present both sides in the body and keep the disagreement honestly under "Open questions" at the end. The spot where the three axes diverge is often the most interesting point in the whole piece — that was a discovery in the writing itself.
The reverse risk: do not get too lazy in the merge. Pasting the three briefs together verbatim produces a "written by a committee" feel, with the tone all over the place. The step where the orchestrator rewrites everything in one first-person voice (ZYL0) cannot be skipped. Subagents gather material; the orchestrator writes in one voice. That division is where I have landed most comfortably.
The mechanism is simple, but operating it surfaces a few landmines. Here are the ones I stepped on.
- Subagent deliverables too long, drowning the main session: A subagent's output returns wholesale into the orchestrator's context. Without a word ceiling in the definition, each axis returns thousands of words and context bursts at the merge. Always write "≤ 300–400 words, fixed headings" into each definition.
- MCP tools get called from non-investment subagents: Forget the
tools:
list and a subagent may default to broad access. List MCP tools that touch sensitive data ONLY in the investment subagent's tools:
, never elsewhere. Even with the server-side guard from last post, scope twice to be safe. - Telling subagents to "stay consistent": Each subagent cannot see the other axes' results. Ask it to reconcile and it starts filling gaps from imagination. Centralize consistency judgment in the orchestrator.
- "Parallel" silently running sequential: Without an explicit "in parallel," agents may run one at a time, killing the speed benefit. Always write "launch in parallel" in the orchestrator prompt — and since behavior can change by version, verify in the trace that they truly ran concurrently.
- Investment subagent fetching full bodies: Without "only the 1-2 relevant ones" in the system prompt, it will fetch the body of every hit. Bake last post's tool design (search to triangulate, then fetch) explicitly into the subagent's Steps.
These are the "not in the official docs, but obvious once you hit them" kind. Writing them down for my future self.
A wider take to close. After standing up three subagents, what I noticed is that this is not about cloning myself into three people — it's about drawing boundaries around research.
Investment, technical, reader-need: those three axes have always been separate in my head. But doing them sequentially in one session let the axes bleed together, until even I was fuzzy on where verified ended and imagination began. Splitting them into subagents — with tool scopes and output formats fixed per axis — externalized that boundary into definition files. Not having to re-make the same judgment every time is, in the end, the same benefit I wrote about for Skills in the Skill post.
And being able to reuse last post's MCP server as the investment axis's data source was the most satisfying part to design. Build "a tap into internal knowledge" over MCP once, and it is shared by both the orchestrator and the subagents. Tools, once built, get reused — an obvious thing that really starts to pay off when combined with subagents.
You do not need perfect orchestration. Drop the three agent definitions into
.claude/agents/
and run them in parallel on your next post. If it feels heavy, go back to sequential — that is all. Writing one post teaches you your own pattern far faster than designing a perfect auto-writing pipeline on a whiteboard.
Next Issue Ideas
- Idea 1: Validate Subagent Deliverables with Hooks Before Merging — Auto-check each axis's returned brief with PostToolUse/Stop hooks before the merge. Mechanically reject missing versions, over-length output, and quoted internal-only text so the orchestrator only ever receives clean material — built out as copy-pasteable templates.
- Idea 2: Let the Investment Subagent Analyze EU ETS / THETIS-MRV Primary Data — Have the investment subagent directly analyze public primary data (EU ETS, THETIS-MRV fleet data) and combine it with the internal MCP server to thicken the investment brief. I'll cover a design that keeps fetch, preprocessing, and summarization inside the subagent.
- Idea 3: Package the Orchestration as a Reusable Skill — Bundle this post's orchestrator prompt and three subagent definitions into a single Skill so "parallel research" is one command away. I'll lay out how to split responsibilities across the Skill / subagent / MCP layers, from an implementer's view.
- Claude Skills, MCP, Website Generation, and Programmatic Video in Production: A Practical Engineer's Guide 2026 — Claude Code skills, MCP server building, website generation, and Remotion programmatic video — a practical engineer's …
- Running AI Agents as an Organization: A 12-Subagent, Neon-Backed Postgres Task Board Architecture for a One-Person Company — The era of letting one AI do everything is over.
- Claude Code 2026 Feature Roundup: Putting 1M Context, Skills, Hooks, Subagents, MCP, and Plan Mode to Real Work — Six Claude Code features ordered by adoption priority — 1M context, Skills, Hooks, Subagents, MCP, and Plan Mode — wit…
The factual and numerical assumptions in this article are anchored to primary or public materials that readers can revisit during AdSense review and future updates.
This article is for informational purposes only and does not constitute investment advice or a recommendation of any specific stock, service, or contract structure. The author may hold positions or interests related to companies or services mentioned. Generative AI was used for parts of research, translation, and proofreading, with final review by ZYL0. See the disclaimer for details.