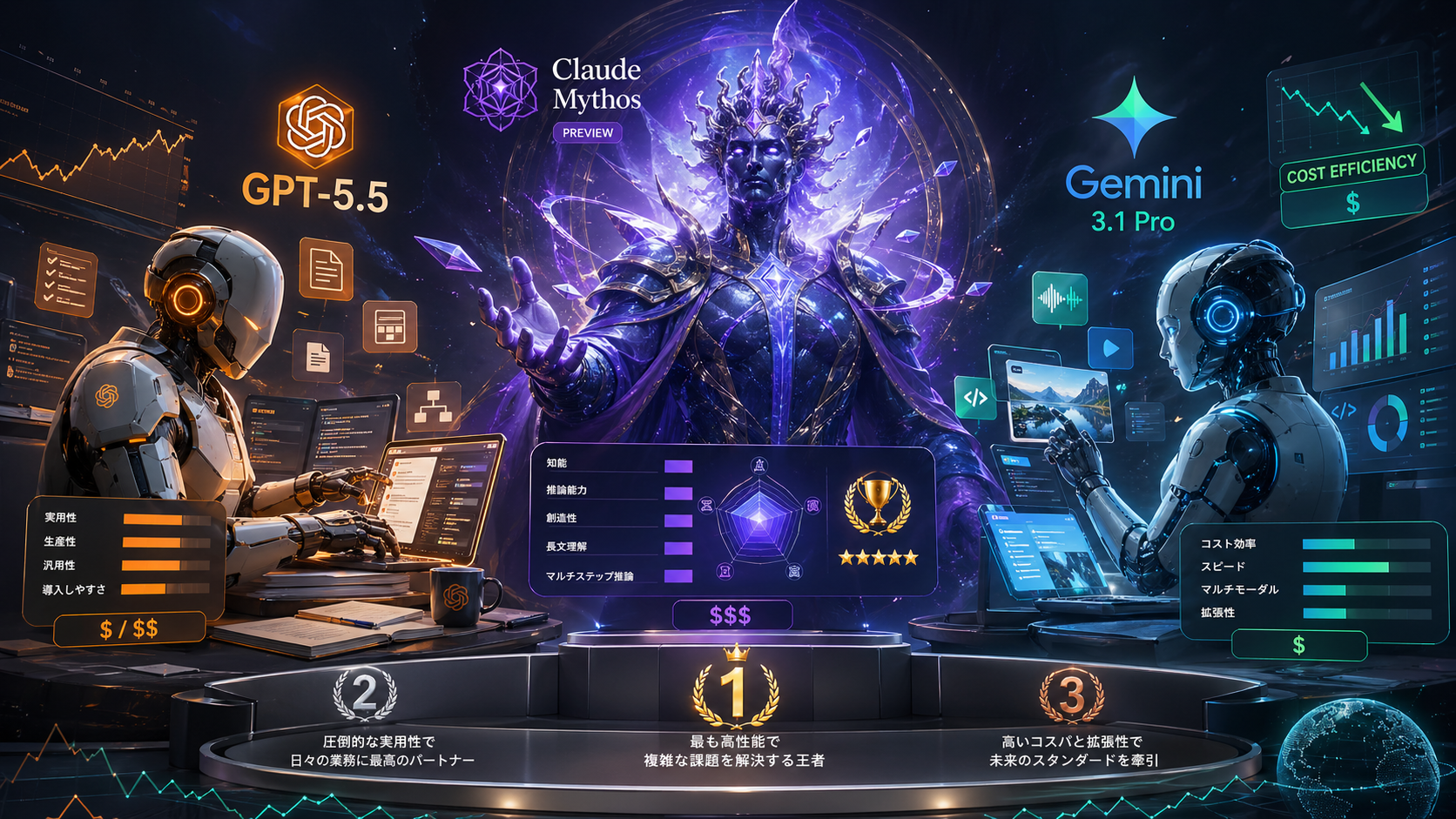
GPT-5.5は「仕事で使えるAI」——だがMythosの背中は遠い
私はCVCで投資メモ・決算分析・英文ピッチ仕分けを毎日AIに走らせ、Claude Codeでブログ実装を回している人間です。3社のフラッグシップを並列で自腹のサブスクと業務アカウントの両方で日常的に使っているからこそ、ベンチマークと実務感覚のずれが見えてきます。今回のGPT-5.5・Mythos・Gemini 3.1 Proの三つ巴は、過去2年で最も「数字より実務感覚が結論を変えた」局面でした。投資家としての含意までを、その手応えで書きます。
最初に、現状をフラットに置きます。
2026年4月23日、OpenAIは最新フラッグシップモデルGPT-5.5(コードネーム「Spud」)を発表しました。前モデルGPT-5.4からわずか6週間という異例のスピードでのリリース。GPT-4.5以来となるフルスクラッチの基盤モデル再学習を行った初のモデルであり、テキスト・画像・音声・動画を単一システムで処理するネイティブ・オムニモーダル設計が採用されている。
率直に言って、GPT-5.5は「仕事でちゃんと使えるAI」に仕上がっている。事前学習の強化により推論の無駄が削ぎ落とされ、処理速度はGPT-5.4と同等を維持しながら性能が底上げされた。計画立案→ツール選択→出力の自己検証という一連のワークフローを、人間の介入を最小限に抑えて実行できる。AIが「質問に答える相手」から「仕事を一緒に片付けるパートナー」に変わったという実感がある。
しかし、Mythosのレベルには達していない。4月7日にAnthropicが発表したClaude Mythos Previewの衝撃が冷めやらぬなか、GPT-5.5はClaude陣営にすぐに追いつけない現実を露呈した。ベンチマークの数字を見れば一目瞭然だし、実際に両方を使い比べてみても、Claudeの「地頭の良さ」は明らかに一段上だ。裏を返せば、Claudeの一人勝ち状態は当面揺るがない。
2026年4月末時点で、OpenAI・Anthropic・Googleの3社がほぼ同時期に最新モデルをリリースし、AI業界は過去最大級の性能競争に突入している。各社のフラッグシップを整理してみたい。
GPT-5.5の設計思想は明確だ。OpenAI自身がこのモデルを「実務とエージェントのための新しい知能クラス」と位置づけている。社内コードネームの「Spud(じゃがいも)」が象徴的で、派手さよりも日常の泥くさい仕事をじっくり片付ける方向に振った印象だ。
コンテキストウィンドウは 100万トークン(API)。大規模なコードベースや社内ドキュメント群を丸ごと読み込み、そこに対してエージェントが自律的に作業する設計だ。最大出力は128,000トークン。学習・推論基盤にはNVIDIAのGB200とGB300 NVL72が使われている。
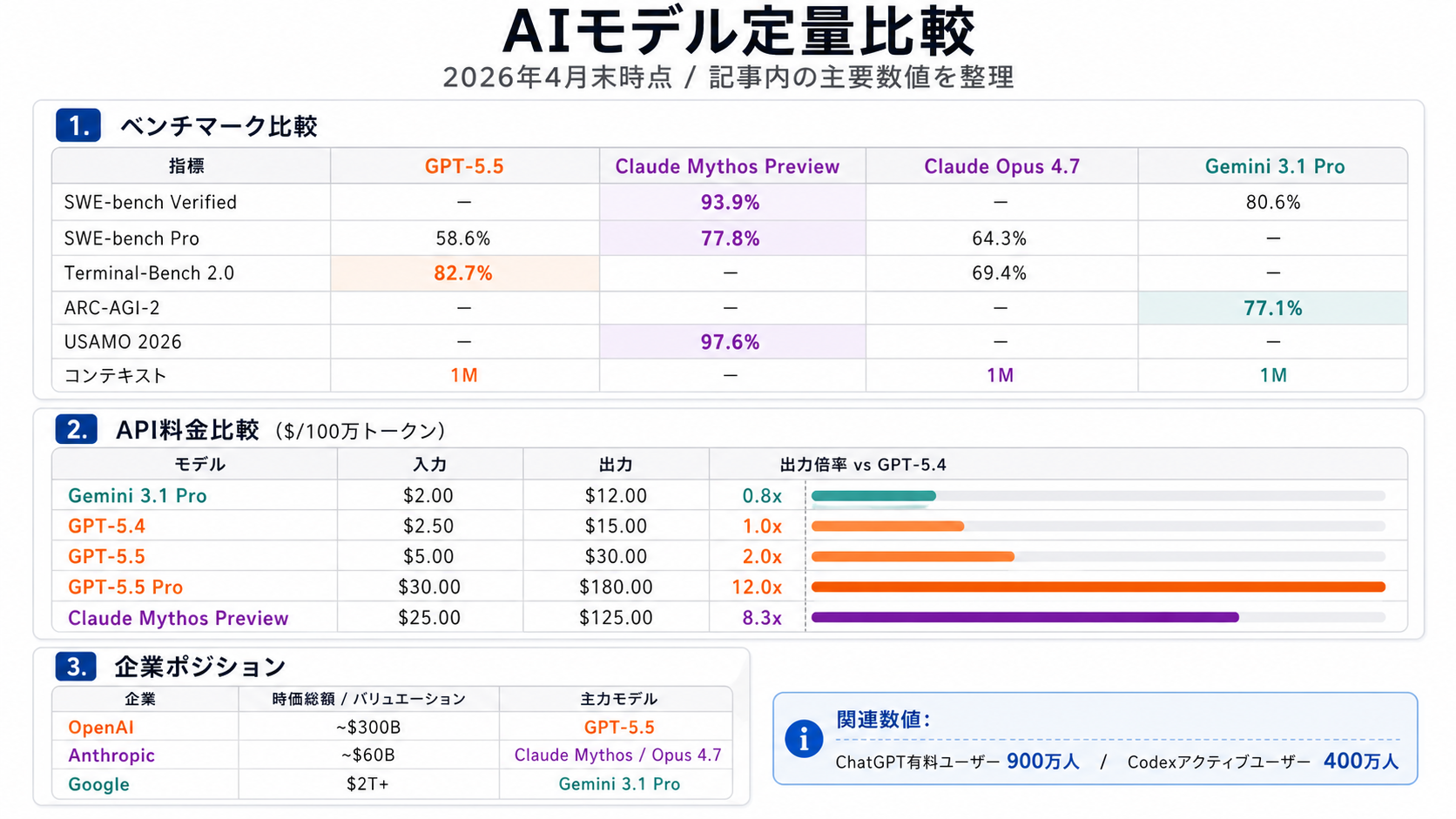
ベンチマークを見ると、GPT-5.5の特性がよく分かる。Terminal-Bench 2.0(CLI上の複合ワークフロー評価)で 82.7% を記録し、Claude Opus 4.7の69.4%を明確に上回った。一方、実践的なソフトウェアエンジニアリング能力を測るSWE-Bench Proでは 58.6% と、Claude Opus 4.7の64.3%には及ばない。つまり、GPT-5.5は「ツール連携を伴う長い作業フロー」に強く、「単独のコーディング精度」ではまだClaudeに分がある。この棲み分けは面白い。
ChatGPTの企業向けには Workspace Agents が実装された。ユーザーがPCをオフラインにした後もクラウド上で自律的に動作し続け、Google Driveなどの外部アプリと連携する。従来のCustom GPTsを置き換える位置づけだ。部門横断の手作業を削減し、長期的な業務プロセスを自動化する——これはエンタープライズ市場への本格的な攻勢と見るべきだろう。
Claude Mythos Previewは間違いなく2026年最大のAIイベントだ。Anthropic史上最強のフロンティアモデルで、コードネームは「Capybara」。だが、このモデルは 一般公開されていない。理由はシンプルに「強すぎるから」だ。
スコアを並べると異次元さが伝わる。SWE-bench Verifiedで 93.9%(Opus 4.6の80.8%から大幅躍進)、SWE-bench Proで 77.8%(GPT-5.4の57.7%を圧倒)、自律的なPC操作能力のOSWorldで 79.6%、数学競技のUSAMO 2026で 97.6%。すべての主要ベンチマークで既存モデルをぶっちぎった。
非公開の最大の理由はサイバーセキュリティ能力にある。Anthropicのレッドチームによるテストで、MythosはWindows、macOS、Linuxの主要OSや全主要Webブラウザに潜むゼロデイ脆弱性を 数千件 自律的に発見した。OpenBSDに27年間潜んでいた脆弱性さえ特定し、攻撃用のエクスプロイトコードまで自動生成した。米財務長官とFRB議長が金融インフラへのリスクを緊急協議したというのだから、その衝撃の大きさが分かる。
Anthropicはこの能力を防御側に活用するため、Apple・Google・Microsoft・NVIDIA等と連携する Project Glasswing を立ち上げた。参加組織に最大$100M相当のAI利用クレジットを提供し、重要ソフトウェアの脆弱性を先回りで修正する試みだ。Mythos PreviewのAPI料金は入力$25/百万トークン、出力$125/百万トークンと、GPT-5.5の5倍以上になる。
ここで考えるべきは、なぜAnthropicだけがこの性能水準に到達できたのか、だ。自分なりの仮説は 「秘伝のタレ」 ——事前学習データのキュレーション品質、RLHF(人間のフィードバックによる強化学習)の洗練されたノウハウ、あるいは潜在空間での推論と再帰的深さ(Recurrent Depth)という新アーキテクチャの組み合わせだろう。いずれか1つではなく、これらが複合的に作用して「地頭の良さ」を生み出している。この優位性は一朝一夕で模倣できるものではないと見ている。
4月16日にリリースされたClaude Opus 4.7もこの文脈で読むべきだ。Opus 4.6から顕著な改善が見られるが、Mythosほどの幅広い能力は備えていない。ただし、Mythosの危険な出力を防ぐセーフガードを最初にテストするモデルとして設計されており、将来的なMythos級モデルの一般公開への布石と理解している。
Gemini 3.1 ProはGoogle DeepMindが2月19日にリリースした最新モデルだ。Transformer MoEアーキテクチャを採用し、ARC-AGI-2(新しいロジックパターンを解く能力)で 77.1%(前モデルの2倍以上)と、推論能力の劇的な向上を見せた。リリース当時はClaude Opus 4.6を上回り、一時的にトップに立った。
100万トークンのコンテキストウィンドウ、テキスト・画像・動画・音声・PDFの統合理解、SVGアニメーションの自動生成やリアルタイムデータからのダッシュボード作成など、実務機能は正直かなり充実している。API料金は入力$2/百万トークン、出力$12/百万トークンと、3社の中で 最もコスト効率が高い のも見逃せない。
問題は、4月のMythos発表以降に相対的なポジションが大きく後退したことだ。率直に言って、Googleは焦っている と思う。Jules(エージェント型コーディングツール)やAntigravity(エージェント開発プラットフォーム)を急ピッチで展開しているが、Claude CodeやOpenAI Codexに対する差別化が見えにくい。モデル性能そのもので頂点を取れないフラストレーションが透けて見える。
ただし、GoogleにはAndroidエコシステム、Google Workspace統合、そして最大のコスト効率というディストリビューション優位がある。性能一点張りではない「別の勝ち筋」が存在することは認識しておくべきだ。
| 指標 | GPT-5.5 | Claude Mythos Preview | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|
| SWE-bench Verified | — | 93.9% | — | 80.6% |
| SWE-bench Pro | 58.6% | 77.8% | 64.3% | — |
| Terminal-Bench 2.0 | 82.7% | — | 69.4% | — |
| ARC-AGI-2 | — | — | — | 77.1% |
| USAMO 2026 | — | 97.6% | — | — |
| コンテキスト | 1Mトークン | — | 1Mトークン | 1Mトークン |
| API入力料金/Mトークン | $5.00 | $25.00 | — | $2.00 |
| API出力料金/Mトークン | $30.00 | $125.00 | — | $12.00 |
今回の3社比較で最も見落とされがちだが、投資家として最も気になるのは 推論コストの急激な高騰 だ。
GPT-5.5のAPI料金は入力$5/百万トークン、出力$30/百万トークンで、GPT-5.4(入力$2.50、出力$15)から ちょうど2倍 に上昇した。上位版GPT-5.5 Proは入力$30、出力$180とさらに高額だ。Claude Mythos Previewに至っては入力$25、出力$125と、GPT-5.5の5倍、Gemini 3.1 Proの10倍以上のコストがかかる。
このコスト構造は、将来的に深刻な 「AI格差」 を生み出すリスクを孕んでいる。最先端のAIモデルを使いこなせる企業・個人と、そうでない層の間で、生産性・創造性・情報アクセスの格差が拡大する構図だ。無料ユーザーはGPT-5.5の恩恵を受けられず、前世代を使い続けることになる。少なくともPlus(月額$20)以上が前提になる世界は、AIの民主化という理念とは逆方向に進んでいる。
| モデル | 入力/Mトークン | 出力/Mトークン | GPT-5.4比(出力) |
|---|
| Gemini 3.1 Pro | $2.00 | $12.00 | 0.8倍 |
| GPT-5.4 | $2.50 | $15.00 | 1.0倍(基準) |
| GPT-5.5 | $5.00 | $30.00 | 2.0倍 |
| GPT-5.5 Pro | $30.00 | $180.00 | 12.0倍 |
| Claude Mythos Preview | $25.00 | $125.00 | 8.3倍 |
特にエージェント系の処理はツールの試行錯誤で出力トークンが膨らみやすい。「気づくと月次費用が想定を大幅に超えていた」というケースは、今後かなり頻発するだろう。モデルの巨大化と性能向上は、必然的にインフラコストの上昇を伴う。これはNVIDIA株の追い風であると同時に、AIスタートアップの損益分岐点を押し上げる逆風でもある。
ここ数ヶ月で最も激化しているのが コーディングAI競争 だ。OpenAIのCodex(アクティブユーザー400万人)、AnthropicのClaude Code、GoogleのJules/Gemini Code Assist/Gemini CLI——3社すべてがAIエージェントによるソフトウェア開発の自動化を最重要テーマに据えている。
なぜコーディングなのか。理由は明確で、コーディング支援はAIの「目に見える生産性向上」を最も直接的に示せる分野だからだ。GitHubのIssueを読んで、該当コードを探し、修正して、テストを流して、プルリクを作る——この一連の作業を自律的に実行できるAIは、エンジニアの生産性を何倍にも引き上げる。そして、その価値に対してエンタープライズ顧客は高い対価を払う用意がある。
GPT-5.5のCodexではブラウザ操作が拡張され、Webアプリとのインタラクション、テストフロー実行、スクリーンショットのキャプチャと反復改善が可能になった。ただし、コーディング精度のベンチマーク(SWE-bench系)では依然としてClaude陣営が優勢だ。Claude Mythos PreviewのSWE-bench Verified 93.9%は、自律的なコード修正能力が人間のシニアエンジニアに接近していることを意味する。この数字は衝撃的だ。
もう一つ注視すべきは、「AIがAIを育てる」合成データ のトレンドだ。AIモデル自身が生成した学習データを使って次世代モデルを訓練する手法は、データの質と多様性を確保できる一方で、モデルの偏りが世代を超えて増幅されるリスクがある。この領域での技術差が、今後のモデル性能の分岐点になるのではないか。Anthropicがこの点で何らかのブレークスルーを持っている可能性は、Mythosの性能を見る限り、かなり濃厚だと考えている。
| 企業 | 時価総額/バリュエーション | 主力モデル | 差別化の軸 | 収益モデル |
|---|
| OpenAI | ~$300B(推定) | GPT-5.5 | 実務エージェント+Codex | サブスク$20〜$200/月+API |
| Anthropic | ~$60B(推定) | Claude Mythos/Opus 4.7 | 技術的優位+安全性 | API+Claude Code+企業向け |
| Google | $2T+(GOOGL) | Gemini 3.1 Pro | エコシステム統合+コスト効率 | 広告+Cloud+サブスク |
三者三様の戦い方が見えてきた。OpenAIは「実務で使える」を旗印にエンタープライズ浸透を狙い、Anthropicは技術的な突出で「頂点」を維持し、Googleはエコシステムとコスト効率で広く薄く取る。AIの「Windows vs Mac vs Linux」とでも言うべき構図が固まりつつある。
| シナリオ | 想定される展開 | 投資含意 |
|---|
| ベースケース | 3社が性能面で拮抗し、差別化はエコシステムとユースケースで決まる | Googleのディストリビューション優位が活きる。GOOGL安定 |
| メインシナリオ | Claudeの技術的優位が持続。Mythos級モデルの一般公開は2027年以降 | Anthropic IPOが2027年の大型テーマに。プレIPO投資機会 |
| テールリスク(上振れ) | AI性能が急速に天井に到達し、差別化がアプリケーション層に移行 | インフラ企業(NVIDIA等)よりアプリケーション企業が恩恵 |
| テールリスク(下振れ) | コスト高騰でAI投資ROIが疑問視される。「AIバブル」崩壊 | テック株全般に調整圧力。ただしAI必需品化で底は浅い |
Claude Mythosの一般公開時期 — セーフガードの構築が進めば段階的な公開が見込まれるが、時期は不透明。公開されれば、AI業界の勢力図が一変する可能性がある。
OpenAI IPOの動向 — ChatGPTの有料ユーザー900万人、Codexの400万人という数字がバリュエーションを支えるが、コスト構造の持続可能性が問われる。GPT-5.5のAPI料金2倍という値上げが、成長率にどう影響するかを注視すべきだ。
推論コスト低減技術の進展 — モデルの蒸留、量子化、推論専用チップの開発が市場全体のTAMを決定する。NVIDIAの次世代チップロードマップ、GoogleのTPU、AmazonのTrainiumの動向が鍵になる。
エージェント型ワークフローのB2B浸透 — GPT-5.5のWorkspace Agents、Claude Code、Gemini Agentsがどれだけエンタープライズ市場に食い込むかが、各社の収益成長を左右する。2026年後半の採用データが最初の試金石だ。
AI規制の加速 — Mythosの「強すぎて出せない」という前例は、AI規制の議論に新しい次元を加えた。EU AI規制法との整合性、各国政府の対応が業界全体のバリュエーションに影響する。
結論として、AI競争は 「性能の頂点」から「実務での浸透」 へフェーズ移行しつつある。GPT-5.5は「仕事でちゃんと使えるAI」として着実に進化し、Mythosという「怪物」はAnthropicの技術的突出を証明した。Googleはコスト効率とエコシステムで別の勝ち筋を模索している。3社の戦略差がこれほど鮮明になった瞬間は過去になく、投資家にとってはポジションを見極める好機だろう。
- 案1:数字で追う続編 — 本記事の前提を最新データで更新し、何が強まり、何が崩れたかを再点検する。
- 案2:実務テンプレート編 — 読者が自分の投資判断、制作単価、または開発運用に転用できるチェックリストへ落とし込む。
- 案3:反対シナリオの検証 — 今回の見立てが外れる条件を先に定義し、次に見るべき指標と時間軸を整理する。
本文の事実関係と数値前提は、再審査時にも読者が確認できる一次情報・公的資料を優先して見直しています。
本記事は情報提供を目的としたものであり、特定の銘柄、サービス、契約条件の推奨や投資助言ではありません。執筆者は記事内で触れた銘柄やサービスにポジションまたは利害関係を持つ可能性があります。調査、翻訳、校正の一部に生成AIを利用していますが、最終的な内容はZYL0が確認しています。詳細は免責事項をご確認ください。
GPT-5.5 Is Finally "AI That Works at Work" — But Mythos Is Still Far Ahead
I run investment memos, earnings analyses, and English pitch-email triage through AI every day from the CVC seat, and I maintain this blog through Claude Code. I pay for all three flagships out of pocket and have enterprise accounts — which means I see where benchmarks diverge from real working feel. The three-way clash between GPT-5.5, Mythos, and Gemini 3.1 Pro is the most "live working feel changed my conclusion" moment of the last two years. The investor implications follow that hands-on read.
Let me put the state of play down flat first.
On April 23, 2026, OpenAI announced its newest flagship, GPT-5.5 (codename "Spud"), shipped just six weeks after GPT-5.4 — an unusually short cadence. It is the first OpenAI model since GPT-4.5 trained from scratch as a foundation model, and the first to use a native omnimodal architecture that handles text, images, audio, and video in a single system.
To put it plainly: GPT-5.5 is finally "AI that actually works at work." Stronger pre-training has stripped reasoning waste, latency stays roughly on par with GPT-5.4, and end-to-end performance moves up. It can run plan → tool selection → self-verification cycles with minimal human intervention. AI has shifted, in my view, from "something I ask questions to" into "a partner that gets work done with me."
But — it has not reached the level of Mythos. Anthropic's Claude Mythos Preview was announced on April 7, and the shockwave has not faded. GPT-5.5 makes it brutally clear that catching up to Claude is not happening overnight. The benchmarks tell the story, and side-by-side use confirms it: Claude's raw "smarts" are visibly a tier above. The flip side is that Claude's solo lead is unlikely to be challenged for some time.
As of late April 2026, OpenAI, Anthropic, and Google have all refreshed their flagships in near lockstep, and the AI industry is in the most intense capability race we've seen.
GPT-5.5's design intent is unambiguous. OpenAI itself frames it as "a new intelligence class for real work and agents." The internal codename "Spud" (potato) feels apt: not flashy, but built to grind through mundane day-to-day work.
Context window: 1M tokens (API). The design assumption is that an agent loads an entire codebase or internal documentation set and works autonomously over it. Max output is 128K tokens. Training and inference run on NVIDIA GB200 and GB300 NVL72.
Benchmarks define the personality. Terminal-Bench 2.0 (CLI multi-step workflow evaluation) hits 82.7%, clearly ahead of Claude Opus 4.7 at 69.4%. But on SWE-Bench Pro — the harder real-world software-engineering benchmark — GPT-5.5 lands at 58.6%, behind Claude Opus 4.7's 64.3%. Translation: GPT-5.5 is strong on long, tool-using workflows, while Claude still leads on pure coding precision. That split is interesting.
For enterprise ChatGPT, OpenAI shipped Workspace Agents: cloud-resident agents that keep running after the user closes their laptop, integrated with Google Drive and other external apps. They effectively replace Custom GPTs. The pitch — eliminate cross-team manual work, automate long-running business processes — reads as a serious enterprise push.
Claude Mythos Preview is, without question, the biggest AI event of 2026. It is Anthropic's strongest frontier model ever, codename "Capybara." But it is not generally available. The reason is simple: it is too strong.
The numbers are out of distribution. SWE-bench Verified at 93.9% (Opus 4.6 was 80.8%). SWE-bench Pro at 77.8% (GPT-5.4: 57.7%). OSWorld autonomous PC control at 79.6%. USAMO 2026 math at 97.6%. It dominates every major benchmark.
The deepest reason for the limited release is cybersecurity capability. In Anthropic red-team tests, Mythos autonomously discovered thousands of zero-day vulnerabilities across Windows, macOS, Linux, and every major web browser. It even surfaced a 27-year-old OpenBSD vulnerability and auto-generated working exploit code. The U.S. Treasury Secretary and the Fed Chair reportedly held an emergency consultation about systemic risk to financial infrastructure — that scale of impact is the signal.
To redirect the capability to defense, Anthropic launched Project Glasswing, partnering with Apple, Google, Microsoft, NVIDIA, and others. Participating organizations get up to $100M of AI usage credits to proactively patch critical software. Mythos Preview API pricing is $25 per million input tokens and $125 per million output tokens — over 5× GPT-5.5.
The real question is why only Anthropic reached this level. My working hypothesis is the "secret sauce" — pre-training data curation quality, refined RLHF craftsmanship, and possibly an architectural combination involving latent-space reasoning and "Recurrent Depth." Not any one of these alone, but the compound effect, is what produces the raw intelligence. I don't think the gap closes in months.
Claude Opus 4.7, released April 16, should be read in this same context. It improves notably on Opus 4.6 but lacks Mythos-class breadth. Its real role is to be the first vehicle for testing Mythos-grade safety guardrails — a stepping stone for eventually shipping Mythos-class capability to the public.
Gemini 3.1 Pro is Google DeepMind's latest, released February 19. It uses a Transformer MoE architecture and posted 77.1% on ARC-AGI-2 (more than 2× the prior generation), a step-change in abstract reasoning. At launch it actually overtook Claude Opus 4.6 and briefly held the top spot.
It also delivers strong product surface: 1M-token context, unified text/image/video/audio/PDF understanding, automated SVG animation, real-time data → dashboard generation. API pricing of $2 per million input tokens and $12 per million output tokens makes it the most cost-efficient flagship of the three.
The problem is positioning post-Mythos. Frankly, Google looks rattled. Jules (agentic coding tool) and Antigravity (agent development platform) are shipping fast, but their differentiation against Claude Code and OpenAI Codex is hard to read. The frustration of not topping pure model performance is visible.
That said, Google still has the Android ecosystem, Workspace integration, and best-in-class cost efficiency — a distribution moat. There is a real "different way to win" beyond raw capability that should not be underestimated.
| Metric | GPT-5.5 | Claude Mythos Preview | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|
| SWE-bench Verified | — | 93.9% | — | 80.6% |
| SWE-bench Pro | 58.6% | 77.8% | 64.3% | — |
| Terminal-Bench 2.0 | 82.7% | — | 69.4% | — |
| ARC-AGI-2 | — | — | — | 77.1% |
| USAMO 2026 | — | 97.6% | — | — |
| Context | 1M tokens | — | 1M tokens | 1M tokens |
| API input $/1M tokens | $5.00 | $25.00 | — | $2.00 |
| API output $/1M tokens | $30.00 | $125.00 | — | $12.00 |
The most overlooked storyline in the three-way comparison — and the one I care about most as an investor — is the sharp rise in inference cost.
GPT-5.5 API pricing is $5 per million input tokens and $30 per million output tokens — exactly 2× GPT-5.4 ($2.50/$15). The premium GPT-5.5 Pro is $30/$180. Claude Mythos Preview at $25/$125 is over 5× GPT-5.5 and more than 10× Gemini 3.1 Pro.
This pricing structure carries real risk of generating an "AI divide" — a widening gap in productivity, creativity, and information access between those who can wield frontier models and those who cannot. Free users won't get GPT-5.5 and will stay on the prior generation. A world where Plus ($20/month) is the de facto floor moves in the opposite direction of "democratizing AI."
| Model | Input $/1M | Output $/1M | vs GPT-5.4 (output) |
|---|
| Gemini 3.1 Pro | $2.00 | $12.00 | 0.8× |
| GPT-5.4 | $2.50 | $15.00 | 1.0× (baseline) |
| GPT-5.5 | $5.00 | $30.00 | 2.0× |
| GPT-5.5 Pro | $30.00 | $180.00 | 12.0× |
| Claude Mythos Preview | $25.00 | $125.00 | 8.3× |
Agentic workloads in particular tend to balloon output tokens via tool retries and self-correction. "My monthly bill came in way over plan" is going to be an extremely common story going forward. Larger, smarter models inevitably mean rising infrastructure cost — a tailwind for NVIDIA, but a headwind on the breakeven economics of every AI startup.
The hottest contested battlefield of the past few months is coding AI. OpenAI's Codex (4M active users), Anthropic's Claude Code, Google's Jules / Gemini Code Assist / Gemini CLI — all three labs have made agentic software development their top priority.
Why coding? Because it is the cleanest place to demonstrate visible AI productivity gains. An agent that can read a GitHub issue, find the relevant code, fix it, run tests, and open a PR multiplies engineer output. And enterprise customers are willing to pay real money for that value.
GPT-5.5's Codex extends browser control: web app interaction, full test-flow execution, screenshot capture, and iterative refinement. But on coding accuracy benchmarks (SWE-bench family), Claude still leads. Mythos Preview's SWE-bench Verified at 93.9% means autonomous code repair is approaching senior-engineer level. That number is genuinely jarring.
The other thing to watch is "AI training AI" via synthetic data. Using model-generated data to train the next generation secures quality and diversity, but risks amplifying biases across generations. Differentiation in this layer is, I suspect, the next inflection point for model performance. Looking at Mythos's level, my prior is high that Anthropic has some kind of breakthrough here.
| Company | Valuation | Flagship | Differentiation | Revenue model |
|---|
| OpenAI | ~$300B (est.) | GPT-5.5 | Practical agents + Codex | Subs $20–$200/mo + API |
| Anthropic | ~$60B (est.) | Claude Mythos / Opus 4.7 | Technical lead + safety | API + Claude Code + enterprise |
| Google | $2T+ (GOOGL) | Gemini 3.1 Pro | Ecosystem + cost efficiency | Ads + Cloud + subs |
Three distinct shapes are emerging. OpenAI pushes "practical at work" to win enterprise. Anthropic holds the summit through technical dominance. Google goes wide and thin on ecosystem and pricing. The AI version of "Windows vs Mac vs Linux" is taking form.
| Scenario | Likely path | Investment implication |
|---|
| Base case | The three converge on capability; differentiation moves to ecosystem and use cases | Google's distribution moat shines. Stable GOOGL |
| Main case | Claude's technical lead persists; Mythos-class GA ships in 2027+ | Anthropic IPO becomes a marquee 2027 theme; pre-IPO opportunity |
| Tail (upside) | AI capability hits a fast ceiling; differentiation shifts to the application layer | Application companies benefit more than infra (NVIDIA et al.) |
| Tail (downside) | Cost spike calls AI ROI into question; "AI bubble" concerns surface | Tech sees broad correction pressure, but bottom is shallow given AI's now-essential nature |
Mythos GA timing — As guardrails mature, a phased release is plausible, but the schedule is unclear. Once it ships, the industry power map can flip overnight.
OpenAI IPO trajectory — 9M paying ChatGPT users and 4M Codex users underwrite the valuation, but cost-structure sustainability is the open question. Watch how the GPT-5.5 2× price hike affects growth.
Inference-cost reduction tech — Distillation, quantization, and inference-specific silicon will determine the total addressable market. NVIDIA's next-gen chip roadmap, Google's TPU cadence, and Amazon's Trainium are key signals.
Agentic workflow B2B adoption — How well GPT-5.5 Workspace Agents, Claude Code, and Gemini Agents penetrate enterprise will dictate revenue growth. H2 2026 adoption data is the first real test.
AI regulation acceleration — Mythos's "too strong to ship" precedent has added a new dimension to the regulatory conversation. EU AI Act alignment and government responses will move sector valuations.
The bottom line: AI competition is shifting from "peak capability" to "practical adoption." GPT-5.5 has matured into an "AI that works at work." Mythos has proven Anthropic's technical lead. Google is hunting a different win via cost and ecosystem. The strategic gap between the three has never been this sharp — for investors, it's a real moment to size positioning carefully.
- Idea 1: A data-updated follow-up — Revisit the thesis with fresh numbers and separate what strengthened from what broke.
- Idea 2: A practical template edition — Turn the article into a checklist readers can reuse for investing, pricing, or technical operations.
- Idea 3: The bear-case test — Define the conditions that would invalidate this view and map the indicators to watch next.
The factual and numerical assumptions in this article are anchored to primary or public materials that readers can revisit during AdSense review and future updates.
This article is for informational purposes only and does not constitute investment advice or a recommendation of any specific stock, service, or contract structure. The author may hold positions or interests related to companies or services mentioned. Generative AI was used for parts of research, translation, and proofreading, with final review by ZYL0. See the disclaimer for details.