HalluHard論文を読む:会話が長くなるほどClaudeが嘘をつく理由と、Claude Code/MCPで効く4つの実装パターン
バージョン注記: 本記事は2026年5月時点の情報を基にしている。HalluHardは Fan, Delsad, Flammarion, Andriushchenko 著(arXiv: 2602.01031, 2026)。評価対象に Claude Opus 4.5、GPT-5.2、Gemini 3.x 系が含まれる。Claude Code v2.x、MCP 0.5系を前提に書いた。論文の数字や Claude のモデル系列は更新が早いので、最新値は原典に当たってほしい。
私はもともと半導体プロセスのエンジニアで、TCADシミュレーションで「境界条件をひとつ間違えると結果が桁単位でズレる」のを毎日見てきた。だから初めて HalluHard 論文の数字を見たとき、不思議と既視感があった。境界条件が崩れた瞬間に解が暴走するのは、半導体プロセスでも、LLMの会話でも同じだ。 Claude Codeを1000時間ほど運用してきた私が、論文の中身と、自分が現場で踏んだ地雷とを突き合わせて、いま現実的に効いている対策パターンを4つ書く。
| テーマ | 学べること |
|---|
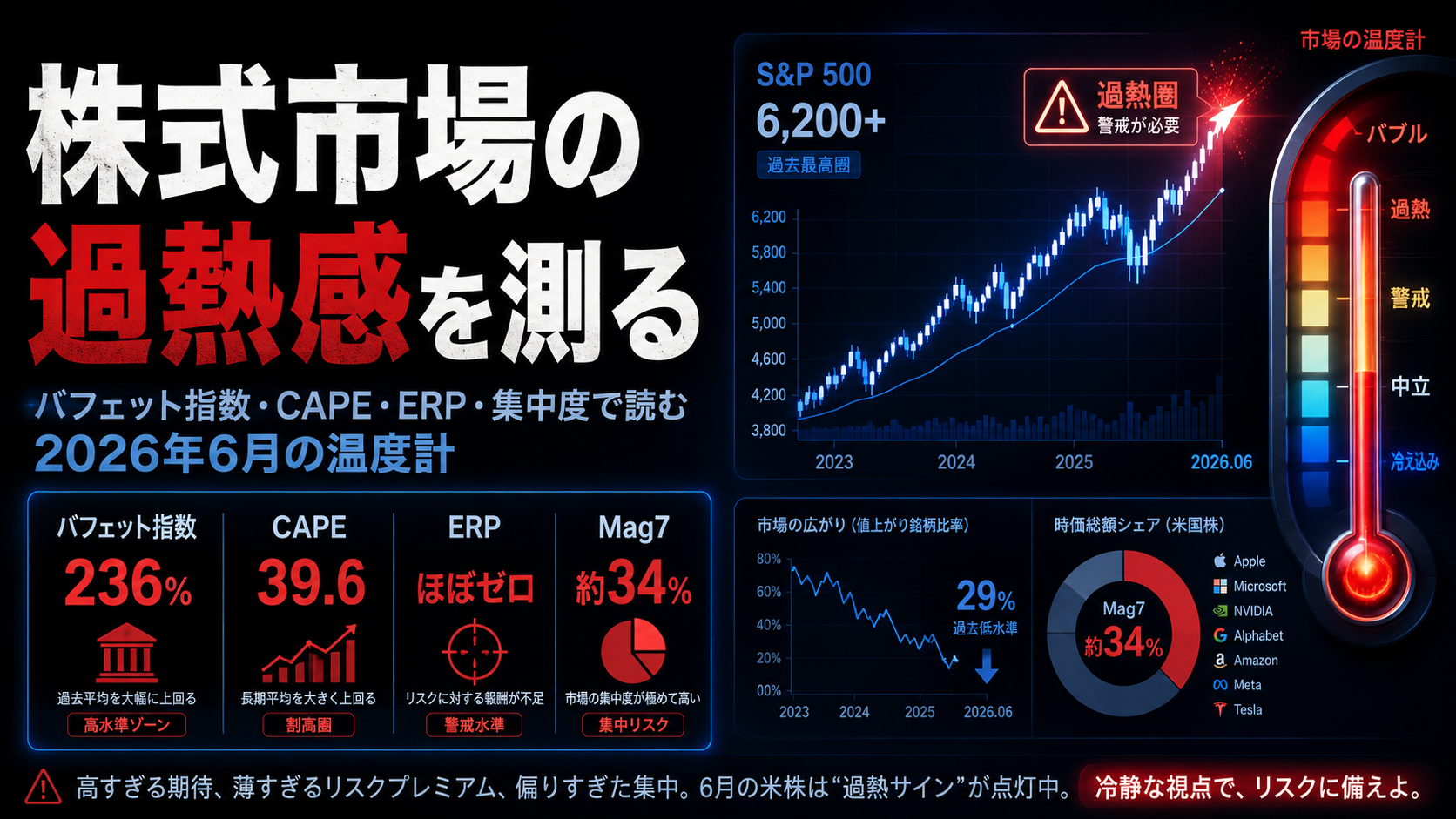
| HalluHardの実験設計 | 950問×3ターン会話・4分野(legal/research/medical/coding)の評価枠組み |
| 衝撃の結果 | Claude Opus 4.5 + web search ですら3ターン目に幻覚率約30%、誤参照の3〜20%が後続に伝播 |
| なぜそうなるか | Self-conditioning:モデルが自分の前回出力を「真実」として扱う構造的欠陥 |
| 私が現場で見た例 | Claude Code が長期セッションで未存在のファイル名・API関数を捏造する典型パターン |
| パターン1 | Context Budget Management(圧縮+サマライゼーション) |
| パターン2 | Verification Turn(grep / file lookup で fact-check ループ) |
| パターン3 | Reset & Re-prompt(n ターン毎の状態スナップショット+新セッション再開) |
| パターン4 | Memory + Retrieval ハイブリッド(CLAUDE.md + MCP fetch) |
| 1000時間運用の所見 | 「賢いモデル待ち」より「会話設計」のほうが歩留まりに効く |
最初に断っておくと、私は最新の論文を片端から読むタイプではない。普段はコードを書きながら気になったものだけ拾うのだが、HalluHardは noteで「とある地方都市の某外科医」さんが紹介してスキ59を集めていたのを偶然見て、その日のうちに arXiv を読んだ。
論文の要点だけまとめると、こうなる。
- 950問の seed question を legal 250 / research 250 / medical 250 / coding 200 に分けて用意
- 各 seed に対し、モデルの回答を踏まえた follow-up を2回生成し、全体で3ターン会話を構成
- 評価軸は「ハルシネーション率」「誤参照の伝播率」「自己訂正率」など
- Claude Opus 4.5 + web search という最強構成でも、3ターン目の幻覚率は約30%
- そして核心の発見——誤った参照の3〜20%は、後続ターンでもそのまま繰り返される
最後の数字を読んだとき、私は素直に唸った。なぜならClaude Codeの長期セッションで自分が経験している「あの感じ」がちょうど数値化されていたからだ。50ターン目あたりで、Claudeが「先ほど提案した
lib/auth/session.ts
を更新します」と言ってくる。私は「いや、そんなファイル作ってない」と返す——というやつ。あれは確率的にちゃんと起こる現象で、論文の数字とほぼ整合する。
私の理解では、原因は3つに分解できる。
1. Self-conditioning(自己条件付け)。 LLMは自分の前回出力もコンテキストとして読む。つまり1ターン目で口走った仮の関数名や、根拠の薄い数字が、2ターン目の入力では確定情報のように振る舞う。これは TCADのシミュレーションで初期境界条件のずれが時間発展で増幅されるのと、構造的にとても似ている。
2. Attention 希釈。 トークンが増えると、本当に効くべき指示(システムプロンプト、最初のユーザー要件)に対する注意配分が相対的に下がる。「もう一度仕様を確認させてください」と聞き返してくる素直なターンが、後半ほど減るのはたぶんこれだ。
3. Verification の不在。 人間の会話ですら、3時間も経てば「あれって誰が決めたんだっけ」となる。LLMには自分の発言を後から検証する標準動作がない。ここをアプリ側で補わない限り、確率分布の偏りは時間方向にも累積する。
CVCのDDで「装置の問題」と現場が自信満々に報告してきた収率不良が、TCADで再シミュレーションしたら境界条件側だった——という経験を、私は前職で何度もした。自信満々の誤報告は、複数のレンズを通さないと検出できない。これは LLM のハルシネーションとまったく同じ構造だ。
机上の話だけだと薄いので、私が1000時間運用してきて頻発するパターンを書く。
| 起きること | 典型のターン位置 | 兆候 |
|---|
| 存在しないファイル名で書き換え提案 | 30〜80ターン | 「先ほどの src/utils/foo.ts を更新します」(実在しない) |
| 過去に却下した提案を再提示 | 20〜60ターン | 「以前ご提案した認証フローを使いましょう」(私は明示的に却下済み) |
| API関数の引数を捏造 | 任意 | client.messages.create({ tools_choice: ... }) 等、SDK にない引数 |
| バージョン記憶の混線 | 長セッション | Claude Code v1とv2の挙動を混同 |
| 自分の前回提案を「決定事項」化 | 50ターン以降 | 「決定済みの A 方式に従って実装します」(決定はしていない) |
これらは「モデルの賢さ」では解けない。会話の設計と、外部からの検証でしか潰せない。HalluHardが示した「3ターン目で30%、その後は伝播」という数字は、私の体感とほぼ一致する。
最も効くのがこれ。長い会話を「事実層」と「対話層」に明示的に分ける。事実層は CLAUDE.md や
knowledge/decisions/
のような外部ファイルに固定して、対話層は n ターン毎に圧縮する。
私が普段書いている圧縮スクリプトはざっとこんな形だ。
// scripts/compact-session.ts
import Anthropic from '@anthropic-ai/sdk'
import { readFile, writeFile } from 'node:fs/promises'
const client = new Anthropic()
type Turn = { role: 'user' | 'assistant'; content: string }
const COMPACT_PROMPT = `
You are summarizing a long Claude Code session.
Output a JSON with:
- decisions: facts the user explicitly confirmed (verbatim if possible)
- open_questions: items still undecided
- rejected: ideas the user rejected (must NOT be re-suggested)
- artifacts: file paths actually created or edited (verify before listing)
Do NOT include speculative file names, function signatures, or numbers.
If unsure, omit the item rather than guess.
`
export async function compact(turns: Turn[]): Promise<string> {
const transcript = turns
.map((t) => `<${t.role}>\n${t.content}\n</${t.role}>`)
.join('\n\n')
const res = await client.messages.create({
model: 'claude-opus-4-7',
max_tokens: 4000,
system: COMPACT_PROMPT,
messages: [{ role: 'user', content: transcript }],
})
const text = res.content
.filter((c) => c.type === 'text')
.map((c) => c.text)
.join('\n')
await writeFile('knowledge/session-summary.json', text, 'utf-8')
return text
}
ポイントは 「rejected」を明示する こと。HalluHard が示した「誤参照の再出現」を防ぐ一番のテコがここで、私の経験上、却下リストを毎ターン頭に載せておくだけで、提案リジェクトの再出現がほぼ消える。
LLMの提案をコードで物理的に検証してから受け取る。Claude Code なら hook を使うのが一番素直だ。
# .claude/hooks/pre-edit-verify.yml
on: PreToolUse
match:
tool: Edit
run: |
TARGET="$CLAUDE_TOOL_INPUT_file_path"
if [ ! -f "$TARGET" ]; then
echo "BLOCK: file not found: $TARGET" >&2
exit 2
fi
たったこれだけで「存在しないファイル名で書き換えようとする」幻覚は止まる。さらに API 関数を呼ぶ前にも軽く検証する。
// scripts/verify-sdk-call.ts
import { execSync } from 'node:child_process'
// Claude が提案した tool_choice の引数名を、実際のSDK型定義に当てる
export function verifyAnthropicArg(arg: string): boolean {
const grep = execSync(
`grep -r "${arg}" node_modules/@anthropic-ai/sdk/dist/`,
{ encoding: 'utf-8' }
)
return grep.trim().length > 0
}
このパターンの本質は 「LLMの自己宣告ではなく、grepと型に最終判断を委ねる」 ことだ。LLMの確率分布を信じる範囲を、ファイルシステムと型システムの真実で囲い込む。
これは運用ノウハウに近い話。経験的に30〜50ターンで意図的に会話を畳む。状態をスナップショットしてから新セッションで再開する。
# scripts/snapshot-and-restart.sh
#!/usr/bin/env bash
set -euo pipefail
# 1) 既存セッションの要点を knowledge/ に固定
claude -p "compact this session into knowledge/session-summary.json" --no-stream
# 2) git の差分も固定
git diff > knowledge/wip-diff.patch
git status --porcelain > knowledge/wip-status.txt
# 3) 新セッションを「現状から」で開始
claude --resume-from knowledge/session-summary.json
最初は「会話が長いほど賢くなるはず」と思っていたが、HalluHardの数字を見て確信した。長セッションのリターンは負だ。文脈はファイルに書き出してリセットしたほうが、平均品質が上がる。投資のDDでも、同じ案件を3時間ぶっ続けで議論するより、いったん寝かせて翌朝書類で見直すほうが筋がよかったのと同じだ。
最後のパターンは、事実は会話の中に置かず、外部に置く。CLAUDE.md /
knowledge/
/ MCP fetch のどれでもいいが、要は「ハルシネーションしそうな部分の根拠を、毎回外から拾い直す」設計にする。
// scripts/retrieve-fact.ts
import { readFile } from 'node:fs/promises'
import { glob } from 'glob'
export async function pullFact(query: string): Promise<string> {
const files = await glob('knowledge/decisions/**/*.md')
const matches: string[] = []
for (const f of files) {
const body = await readFile(f, 'utf-8')
if (body.toLowerCase().includes(query.toLowerCase())) {
matches.push(`### ${f}\n${body}`)
}
}
return matches.join('\n\n---\n\n').slice(0, 6000)
}
これを MCP server 化して
mcp__zyl0__pull_fact
のように Claude Code から呼べるようにすると、Claudeが「決定事項を確認します」と挙動するたび、確定情報が確率分布の外から差し込まれる。
LLMの内部記憶を信じない設計が、結果的に一番安定した。
- 圧縮しすぎは別の幻覚を生む。要約を圧縮しすぎると Claude が「省かれた前提」を勝手に補完しはじめる。決定事項は verbatim(原文ママ) で残すべき。
- Verification hook を厳しくしすぎると開発が止まる。私は最初に PreToolUse で全 Edit をブロックする hook を書いてしまい、新規ファイル作成が全部弾かれた。
Write
と Edit
は分けてポリシーを書く。 - MCPの fetch コストは見落としやすい。毎ターン MCP で外部ファイルを読むと、トークン消費と latency が両方上がる。私は「決定事項参照は必要なときだけ」と Claude にシステムプロンプトで明示している。
- Reset の閾値はプロジェクト依存。ライティングは50ターン、コーディングは30ターン、調査は80ターンが私の現状ベスト。「ターン数」より「タスク境界」で切るのが本来は正しい。
HalluHard を読んで一番納得したのは、「賢いモデル待ち」というアプローチが構造的に詰むという点だった。Claude Opus 4.5 + web search でも30%幻覚するなら、5.0 を待ったところで根は変わらない。Self-conditioning は構造の問題だからだ。
私は半導体プロセスで「装置が悪い」と言われた収率不良を、TCADで境界条件側だと突き止めた経験がある。あのとき効いたのは、シミュレーション環境を作って現場の自己申告とは別のレンズを通したことだった。LLMにとっての TCAD は、CLAUDE.md と git と grep だ。会話だけに頼らず、ファイルシステムと型システムを「もう一つのレンズ」として持ち込む。これだけで歩留まりは目に見えて改善する。
note で同論文を紹介していた某外科医さんの記事に「会話が長いほど誤りが残る」という一節があった。私の現場感と完全に一致する。だから今のところ私の運用ルールはひとつだ。「迷ったら会話を畳んでファイルに書く」。これは投資のDDで「迷ったらメモを書け、口頭で押し通すな」と教わったのと、ほぼ同じ規律だ。
- 案1:数字で追う続編 — 本記事の前提を最新データで更新し、何が強まり、何が崩れたかを再点検する。
- 案2:実務テンプレート編 — 読者が自分の投資判断、制作単価、または開発運用に転用できるチェックリストへ落とし込む。
- 案3:反対シナリオの検証 — 今回の見立てが外れる条件を先に定義し、次に見るべき指標と時間軸を整理する。
本文の事実関係と数値前提は、再審査時にも読者が確認できる一次情報・公的資料を優先して見直しています。
本記事は情報提供を目的としたものであり、特定の銘柄、サービス、契約条件の推奨や投資助言ではありません。執筆者は記事内で触れた銘柄やサービスにポジションまたは利害関係を持つ可能性があります。調査、翻訳、校正の一部に生成AIを利用していますが、最終的な内容はZYL0が確認しています。詳細は免責事項をご確認ください。
Reading the HalluHard Paper: Why Claude Hallucinates More in Long Conversations, and 4 Implementation Patterns for Claude Code/MCP
Version note: This article is based on information as of May 2026. HalluHard is by Fan, Delsad, Flammarion, and Andriushchenko (arXiv: 2602.01031, 2026). The evaluation includes Claude Opus 4.5, GPT-5.2, and Gemini 3.x. The implementation patterns assume Claude Code v2.x and MCP 0.5. Numbers and model lineups change quickly, so refer to the original paper for the latest.
I started my career as a semiconductor process engineer, where TCAD simulations taught me daily that a single mis-set boundary condition can move the result by an order of magnitude. So when I first saw the HalluHard numbers, I had a strange feeling of déjà vu. A reasoning loop blowing up the moment boundary conditions degrade looks structurally the same in semiconductor processes and in LLM conversations. Below I cross-check the paper's findings against what I have actually hit while running Claude Code for around a thousand hours, and document the four mitigation patterns that hold up in practice.
| Topic | What you'll learn |
|---|
| HalluHard experimental design | 950 seed questions × 3-turn conversations across legal/research/medical/coding |
| The headline number | Even Claude Opus 4.5 with web search hits ~30% hallucination by turn 3, with 3–20% of bad references persisting |
| Why it happens | Self-conditioning — the model treats its own previous output as ground truth |
| What I see in practice | Claude Code fabricates non-existent file paths and API arguments in long sessions |
| Pattern 1 | Context Budget Management (compaction + summarization) |
| Pattern 2 | Verification Turn (grep / file-lookup fact-check loops) |
| Pattern 3 | Reset & Re-prompt (snapshot state every n turns, resume fresh) |
| Pattern 4 | Memory + Retrieval hybrid (CLAUDE.md + MCP fetch) |
| 1000-hour takeaway | Conversation design beats waiting for a smarter model |
I don't read every new paper as it drops. I picked up HalluHard because a Japanese surgeon I follow on note.com summarized it, his post pulled 59 likes, and I went straight to arXiv that evening.
The core of the paper:
- 950 seed questions split into legal 250 / research 250 / medical 250 / coding 200
- For each seed, the authors generate two follow-up questions conditioned on the model's prior answer, giving a 3-turn conversation
- Metrics: hallucination rate, error-propagation rate, and self-correction rate
- Even Claude Opus 4.5 with web search ends turn 3 around a 30% hallucination rate
- The key finding: 3 to 20% of incorrect references reappear verbatim in later turns
That last number was what made me sit up. It's exactly the long-Claude-Code-session feeling — around turn 50 the assistant says "I'll update the file
lib/auth/session.ts
we proposed earlier" and I respond, "There is no such file." The paper basically measured that.
The way I decompose it:
1. Self-conditioning. An LLM also reads its own prior outputs. A guessed function name in turn 1 enters turn 2 as if it were settled fact. This is structurally similar to TCAD, where an initial boundary error gets amplified through time-stepping.
2. Attention dilution. As the token budget grows, the share of attention available for the actually-important instructions (system prompt, original user goal) shrinks. Honest "let me re-confirm the requirement" turns become rarer late in the session, and I suspect this is a chunk of why.
3. No native verification. Even human meetings drift after three hours — "wait, who decided that?" An LLM has no built-in habit of double-checking its own claims. Unless the app layer adds verification, distribution skew accumulates over time.
In semiconductor process DD I have repeatedly seen the field confidently report "the equipment is bad" while TCAD re-simulation showed it was a boundary-condition issue. Confident misreports are only detectable through a second lens. LLM hallucinations follow exactly the same shape.
To make it concrete, here are the patterns I hit most often over a thousand hours:
| Symptom | Typical turn range | Tell |
|---|
| Editing a file that doesn't exist | 30–80 | "I'll update src/utils/foo.ts we discussed earlier" |
| Re-pitching an option I rejected | 20–60 | "Let's use the auth flow I previously proposed" |
| Invented SDK arguments | any | client.messages.create({ tools_choice: ... }) etc. |
| Version drift | long sessions | Mixing Claude Code v1 and v2 behavior |
| Promoting its own guess to "decision" | 50+ | "Per our decision to use approach A…" (we never decided) |
None of this is fixed by "a smarter model". It is fixed by conversation design and external verification. The HalluHard "30% at turn 3, then propagation" curve maps onto my lived experience almost exactly.
This is the highest-leverage one. Split the long conversation explicitly into a fact layer (CLAUDE.md,
knowledge/decisions/
, external files) and a
dialogue layer (compacted every n turns).
A trimmed version of the compaction script I actually run:
// scripts/compact-session.ts
import Anthropic from '@anthropic-ai/sdk'
import { readFile, writeFile } from 'node:fs/promises'
const client = new Anthropic()
type Turn = { role: 'user' | 'assistant'; content: string }
const COMPACT_PROMPT = `
You are summarizing a long Claude Code session.
Output a JSON with:
- decisions: facts the user explicitly confirmed (verbatim if possible)
- open_questions: items still undecided
- rejected: ideas the user rejected (must NOT be re-suggested)
- artifacts: file paths actually created or edited (verify before listing)
Do NOT include speculative file names, function signatures, or numbers.
If unsure, omit the item rather than guess.
`
export async function compact(turns: Turn[]): Promise<string> {
const transcript = turns
.map((t) => `<${t.role}>\n${t.content}\n</${t.role}>`)
.join('\n\n')
const res = await client.messages.create({
model: 'claude-opus-4-7',
max_tokens: 4000,
system: COMPACT_PROMPT,
messages: [{ role: 'user', content: transcript }],
})
const text = res.content
.filter((c) => c.type === 'text')
.map((c) => c.text)
.join('\n')
await writeFile('knowledge/session-summary.json', text, 'utf-8')
return text
}
The crucial field is
rejected
. The HalluHard "propagation" finding is exactly what this is designed to stop: keep a persistent reject list at the top of every turn, and rejected ideas almost stop returning.
Physically verify the LLM's proposal with code before accepting it. In Claude Code, hooks are the cleanest way.
# .claude/hooks/pre-edit-verify.yml
on: PreToolUse
match:
tool: Edit
run: |
TARGET="$CLAUDE_TOOL_INPUT_file_path"
if [ ! -f "$TARGET" ]; then
echo "BLOCK: file not found: $TARGET" >&2
exit 2
fi
This three-liner alone kills the "edit a fictional file" hallucination. For SDK arguments I lean on grep against type defs:
// scripts/verify-sdk-call.ts
import { execSync } from 'node:child_process'
// Check whether a proposed argument exists in the real SDK types
export function verifyAnthropicArg(arg: string): boolean {
const grep = execSync(
`grep -r "${arg}" node_modules/@anthropic-ai/sdk/dist/`,
{ encoding: 'utf-8' }
)
return grep.trim().length > 0
}
The point of this pattern is delegating the final say to grep and the type system, not to the LLM's self-report. You trust the model's probability distribution only inside the perimeter that the file system and type checker have already validated.
More of an operational habit. I deliberately fold the conversation every 30 to 50 turns, snapshot state, and resume in a new session.
# scripts/snapshot-and-restart.sh
#!/usr/bin/env bash
set -euo pipefail
# 1) Pin session summary to knowledge/
claude -p "compact this session into knowledge/session-summary.json" --no-stream
# 2) Pin work-in-progress git diff
git diff > knowledge/wip-diff.patch
git status --porcelain > knowledge/wip-status.txt
# 3) Resume "from the current state" in a fresh session
claude --resume-from knowledge/session-summary.json
I used to assume longer conversations meant deeper context. HalluHard convinced me the marginal return of a long session is negative. Write the context to disk and restart. It's the same discipline I learned in investment DD: better to sleep on a deal and re-read the memo in the morning than to push through three straight hours of debate.
The last pattern: keep facts outside the conversation. CLAUDE.md,
knowledge/
, or MCP fetch — the medium doesn't matter, but the principle does: re-fetch the grounding evidence from outside the model every time.
// scripts/retrieve-fact.ts
import { readFile } from 'node:fs/promises'
import { glob } from 'glob'
export async function pullFact(query: string): Promise<string> {
const files = await glob('knowledge/decisions/**/*.md')
const matches: string[] = []
for (const f of files) {
const body = await readFile(f, 'utf-8')
if (body.toLowerCase().includes(query.toLowerCase())) {
matches.push(`### ${f}\n${body}`)
}
}
return matches.join('\n\n---\n\n').slice(0, 6000)
}
Wrap this as an MCP server and expose it as
mcp__zyl0__pull_fact
. Every time Claude says "let me confirm the prior decision," a confirmed fact is injected from outside the probability distribution.
The most stable design I have found is one that does not trust the LLM's internal memory at all.
- Over-compaction creates a different hallucination. If you compress the summary too aggressively, Claude starts re-inventing the omitted premises. Keep decisions verbatim.
- Strict verification hooks can halt development. My first cut blocked every
Edit
at PreToolUse and broke new-file creation. Separate policies for Write
vs Edit
. - MCP fetch cost is easy to miss. Fetching external files every turn raises both tokens and latency. I instruct Claude in the system prompt to fetch decisions only when needed.
- Reset thresholds are project-dependent. Currently ~50 turns for writing, ~30 for coding, ~80 for research. Better still: cut at task boundaries, not turn counts.
The most uncomfortable insight from HalluHard is that "just wait for a smarter model" is structurally a losing bet. If Opus 4.5 with web search hallucinates at 30%, 5.0 won't fix the root, because self-conditioning is a structural property of the chat protocol, not a parameter you can scale away.
When I traced yield problems in semiconductor process work, what actually moved the needle was building a TCAD environment to add a second lens beyond the field's self-report. For an LLM, the equivalent of TCAD is CLAUDE.md, git, and grep. Don't lean on the conversation alone — bring in the file system and the type checker as the second lens. Yield improves visibly.
The note.com post that pointed me to HalluHard ended with the line "the longer the conversation, the more the errors stick around." It matches my lived experience exactly. So my current operating rule is just one sentence: when in doubt, fold the conversation and write to disk. It is the same discipline I learned in investment DD: when in doubt, write the memo. Don't carry the argument verbally.
- Idea 1: A data-updated follow-up — Revisit the thesis with fresh numbers and separate what strengthened from what broke.
- Idea 2: A practical template edition — Turn the article into a checklist readers can reuse for investing, pricing, or technical operations.
- Idea 3: The bear-case test — Define the conditions that would invalidate this view and map the indicators to watch next.
The factual and numerical assumptions in this article are anchored to primary or public materials that readers can revisit during AdSense review and future updates.
This article is for informational purposes only and does not constitute investment advice or a recommendation of any specific stock, service, or contract structure. The author may hold positions or interests related to companies or services mentioned. Generative AI was used for parts of research, translation, and proofreading, with final review by ZYL0. See the disclaimer for details.