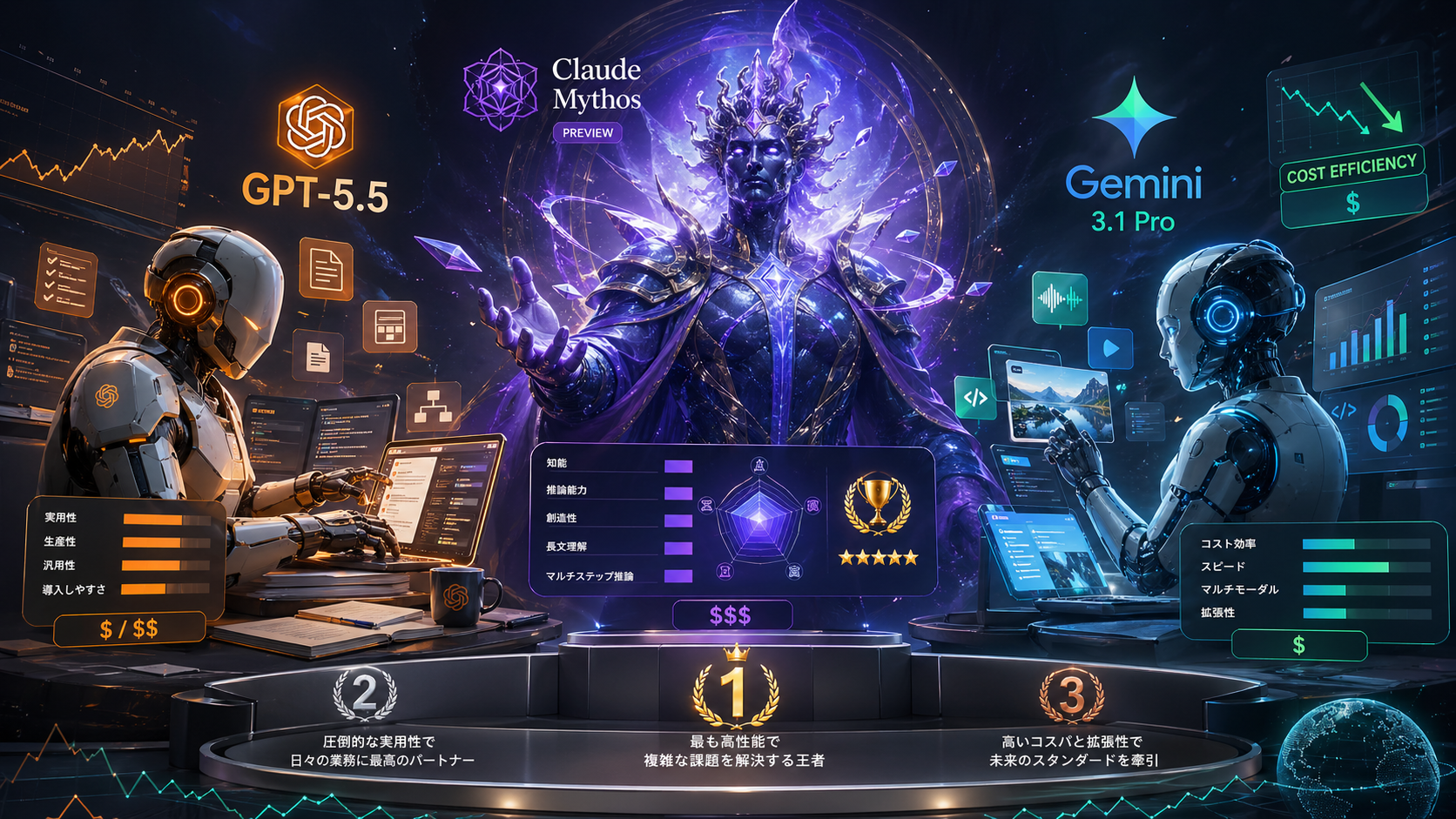
最新Claude・Gemini・ChatGPTを徹底比較|VCの僕がたどり着いた使い分けの結論
ここ1〜2ヶ月で3大AIラボのフラッグシップが立て続けにアップデートされました。OpenAIが2026年3月5日にGPT-5.4(Pro / Thinking)をリリースし、Anthropicは4月16日にClaude Opus 4.7を投入、GoogleもGemini 3からGemini 3.1 Proへと更新。この3モデルが現時点のトップ層です。
私はVCとしてスタートアップの評価書を書いたり、決算短信を要約したり、コードを読んだりと1日中AIを触っているわけですが、正直「1つで全部済ませる」時代はもう終わったと思っています。モデルごとに「尖っている部分」と「鈍い部分」がハッキリ分かれてきているというのが2026年4月時点の実感です。
この記事では、最新3モデルを公式ベンチマークとVC実務での使用感の両面からざっくばらんに比較して、最後に僕自身の使い分けまで公開します。数字マニアックな話というよりは、「で、結局どれをどう使えばいいの?」という実務寄りの話です。

まずはここ2年の流れをざっくり振り返ります。
2024年はGPT-4oが事実上のデファクトスタンダードでしたよね。マルチモーダルも綺麗にまとまっていて、「とりあえずChatGPT Plus契約しとけ」が正解だった時代です。
そこにAnthropicがClaude 3.5 Sonnetで殴り込んできて、特にコーディング性能で「あれ、これGPT-4oより明らかに上手くない?」と業界がざわつき始めます。Cursor、Cline、Aider等のAIコーディングツールが一気にClaudeを標準モデルに据え始めたのがこの頃です。
Geminiは……正直、2024年前半は微妙でした。Gemini 1.5でコンテキスト100万トークンという「量で殴る」戦略は面白かったけど、肝心の回答品質がGPT-4やClaudeに一歩及ばない印象でした。
2025年はとにかく「推論」がキーワードでした。OpenAIがo1 → o3 → o4と推論モデルを連発し、「考えてから答える」パラダイムが定着。AnthropicもClaude 3.7 Sonnetで「Extended Thinking」を搭載、GoogleもGemini 2.5 Proで「Deep Think」モードを用意します。
この流れで、数学・科学・コードといった「正解のある問題」については、どのフラッグシップモデルも博士課程レベルに到達したと言っていい状況になりました。
そして2026年、3社の最新フラッグシップが出揃いました。
- OpenAI: GPT-5.4 Pro(2026年3月5日)
- Anthropic: Claude Opus 4.7(2026年4月16日)
- Google: Gemini 3.1 Pro(Deep Think搭載)
「推論するかどうかをユーザーが切り替える」時代は終わり、モデルが勝手に判断するというのが大きな流れです。ユーザーは質問するだけ。簡単な質問は速く、難しい質問はじっくり——これが標準になりました。
もう一つの潮流は「コンピュータ操作」の実用化。GPT-5.4はOSWorldベンチで75%を記録し、人間の専門家(72.4%)を超えました。「AIがブラウザやPCを動かして仕事をする」段階に突入した年、というのが2026年です。
それでは本題。2026年4月時点の公開ベンチマークと実運用の感触を整理します。
| 項目 | Claude Opus 4.7 | Gemini 3.1 Pro | GPT-5.4 Pro |
|---|
| リリース | 2026年4月16日 | 2026年前半(3.1世代) | 2026年3月5日 |
| SWE-bench Verified | 87.6% | 80.6% | 約82% |
| SWE-bench Pro | 64.3% | 約53% | 約55〜58% |
| GPQA Diamond(科学推論) | 高水準 | 94.3% | 高水準 |
| Humanity's Last Exam | — | 44.4% | — |
| ARC-AGI-2(抽象推論) | — | 77.1% | 83.3% |
| BrowseComp(Web操作) | — | — | 89.3% |
| OSWorld(PC操作) | — | — | 75% |
| MMMU-Pro(マルチモーダル) | ◯ | 80.5% | ◎ |
| コンテキスト長 | 200K(1M版あり) | 1M | 1M〜1.1M |
| 入力価格($/1M tokens) | $5 | 最安水準(約1/5) | $2.50 |
| 出力価格($/1M tokens) | $25 | 最安水準 | $15 |
| 動画・音声ネイティブ | △ | ◎ | ◯ |
① コーディング:Claudeが王座奪還
Opus 4.6→4.7でSWE-bench Verifiedが80.8%→87.6%と7ポイント近くジャンプし、Gemini 3.1 Pro(80.6%)とGPT-5.4(約82%)を抜き返しました。難度の高いSWE-bench Proでは64.3%と、GPT-5.4(約57.7%)・Gemini(約54.2%)を10ポイント以上引き離しています。
CursorBenchも58%→70%と大幅改善。実務で「このリポジトリ全体を読んで設計の問題点を指摘して」系のタスクをやると、体感でもClaudeが一段抜けているのが分かります。
② 科学推論:Geminiが頭ひとつリード
GPQA Diamond 94.3%、MMMLU 92.6%など、研究レベルの知識・推論ベンチでGemini 3.1 Proが最強クラス。Google Researchの基礎研究基盤が効いている印象で、数式や論文読解の厳密性で安定感があります。
③ エージェント・PC操作:GPT-5.4が独走
BrowseComp 89.3%、OSWorld 75%(人間エキスパート72.4%を超える)と、「ブラウザやPCを自動操作する」系のベンチでGPT-5.4 Proが独走しています。ARC-AGI-2でも83.3%と、抽象推論のトップです。
④ 長文コンテキスト:Geminiの1Mが実用性で先行
Claudeも1Mコンテキスト版を提供していますが、ネイティブで1Mを全モデルに提供しているGeminiが量の面で有利。PDF数十本を一気読みさせるような用途では現時点でGeminiが最もコストパフォーマンスが良いです。
⑤ マルチモーダル(動画・音声):Geminiが設計思想で勝つ
Geminiは最初からテキスト・画像・動画・音声・コードを統合設計している強みが効いていて、YouTube動画を直接渡して要約させたり、長尺の会議録音を議事録化するといった用途ではGemini一択の状況です。
⑥ 創作・文章表現:Claudeが依然として好まれる
ブラインドの人間評価で、創作系タスクはClaudeが47%、GPT-5.4が29%、Geminiが24%で選ばれるという結果が出ています。投資メモや編集系の下書きを任せるならClaudeが無難、というのが実感と一致します。
⑦ コスト:Geminiが圧倒的
Gemini 3.1 ProはClaude Opus 4.7のおよそ1/5、GPT-5.4の約1/4の価格帯。バッチ処理や大量データを流すワークロードではGeminiが経済合理性で圧勝します。
性能の話だけだと見えてこない部分として、「サービスとしての使いやすさ・エコシステム」の違いが実はかなり大きいです。
- 強み: コーディング・エージェント特化、創作力、Artifacts、MCP(Model Context Protocol)によるエコシステム拡張、Finance Agent評価トップ水準
- 弱み: 画像生成なし、動画・音声理解はGeminiに劣る、API価格が最も高い($5/$25)
- プラットフォーム: Claude.ai(Web)、Claude Code(CLI)、API、Amazon Bedrock、Google Cloud Vertex AI
Anthropicは明確に「開発者・エンタープライズ特化」に振り切っているのが特徴です。Opus 4.7は「前モデルが緩く解釈していた指示を文字通り実行する」ように調整されていて、プロンプトの設計力が以前より問われるようになりました。Claude Codeは2025年に登場して以降、今では僕のメインIDEになっています。
- 強み: Google検索統合、Workspace連携(Gmail、Drive、Docs)、ネイティブマルチモーダル(動画・音声込み)、1Mコンテキスト標準、圧倒的な低価格、科学・数式ベンチの強さ
- 弱み: コーディングでの細かい詰めが依然として劣る、ブランド的に「とりあえず試す」のハードルが高い
- プラットフォーム: gemini.google.com、AI Studio、Vertex AI、Googleアプリ内統合、Gemini 3.1 Deep Think(Google AI Ultra加入者向け)
Geminiの真骨頂はGoogleエコシステムとの統合。会社メールを全部読んで要約してくれる、Driveのドキュメントを横断検索できる、といった「日常業務」での強さが圧倒的です。Deep Thinkは科学・エンジニアリングの高難度問題向けに別途用意されている専用推論モードで、高度な分析が必要な場面で切り替えて使えます。
- 強み: エージェント(BrowseComp・OSWorld圧倒的)、抽象推論(ARC-AGI-2 83.3%)、プラグイン・GPTsエコシステム、DALL-E/Sora統合、Advanced Voice Mode、Canvas、知名度・ユーザー数
- 弱み: First-token時間が長い(推論モデルなので)、Knowledge cutoffが2025年8月
- プラットフォーム: ChatGPT(Web/アプリ)、API、Microsoft Copilot統合、Pro・Enterpriseプラン限定
GPT-5.4 Proは「コンピュータ操作エージェント」としての完成度が頭ひとつ抜けています。OSWorldで人間エキスパートを超えたのは象徴的で、「ブラウザで調査→スプレッドシート作成→Slackで送信」みたいな複数ステップ業務の自動化はGPT-5.4 Proが最強候補です。音声対話の自然さも依然として業界トップクラス。
最後に、VCとしての僕自身のリアルな使い分けを公開します。3つ全部有料プラン契約しています(経費です)。
用途: コーディング、決算書読解、投資メモ執筆、契約書レビュー、創作・編集系
- この記事もClaudeで下書きを作っています
- Claude Code経由でこのブログのNuxt 3実装をメンテナンス
- 投資先のデューデリ資料(PDF100本超)を1Mコンテキスト版で一気読み
- SWE-bench Pro 64.3%の地力は、大規模コードベースの読解でそのまま体感できる
- 「指示を文字通り実行する」方向の調整が自分のワークフローと相性が良い
用途: リサーチ、Google Workspace連携、動画・音声処理、多言語翻訳、大量バッチ処理
- カンファレンスの録画動画を丸ごと渡して要点抽出
- 会社メールに届く大量のピッチメール(英語・日本語・中国語混在)の仕分け
- Google検索グラウンディングによる「最新情報リサーチ」
- コスパが異常に良いので、量で殴るタスクはGeminiで回す
- 科学系スタートアップのDDではDeep Thinkに切り替え
用途: Web自動操作、画像生成、音声対話、ブレスト、GPTs定型業務
- BrowseCompの強さが効く「10社のIRページを巡回して決算データを抽出」系タスク
- OSWorldが強いのでExcelやGoogle Sheetsへの自動記入も任せられる
- 投資先向けプレゼン用の画像生成(DALL-E/Sora統合)
- 散歩中の音声対話でアイデアの壁打ち
- 「ChatGPTで試したいから」という依頼者が多いので検証用にも必須
「モデル戦争」はもう終わっていて、今は「得意分野の棲み分け」フェーズだと思います。2026年4月の状況を要約するとこうです。
- コーディング・長文読解・創作 → Claude Opus 4.7
- 科学・マルチモーダル・大量処理・コスト → Gemini 3.1 Pro
- Web/PC操作・抽象推論・エコシステム → GPT-5.4 Pro
VCとして1つアドバイスするなら、「月20〜30ドル×3社」をケチらないこと。ワークロードごとに最適モデルが違うので、使い分けた方が圧倒的に生産性が上がります。
ここからが本記事の投資パートです。「どのモデルが勝つか」ではなく、「3社の優劣の振れ方が、関連銘柄にどう波及するか」が投資家にとっての論点です。
| シナリオ | 確率(私見) | OpenAI/MSFT | Anthropic/AMZN-GOOGL | Google/GOOGL | NVDA |
|---|
| A. 三つ巴継続(ベース) | 50% | 中立 | 中立 | やや上方 | コア配分 |
| B. Anthropic先行(Claudeコーディング独走) | 25% | 中立 | 上方修正 | 中立 | コア維持 |
| C. Google逆転(Gemini統合勝ち) | 15% | やや下方 | 中立 | 上方修正 | コア維持 |
| D. OpenAIエージェント独走 | 10% | 上方修正 | 中立 | 中立 | コア維持 |
私の現状の見立てはシナリオAで、向こう12ヶ月は3社が交互にリードを奪い合う展開が続くと見ています。CVCの感覚で言うと、こういう時期にいちばん効くのは「三社いずれが勝っても恩恵を受ける銘柄」——具体的にはNVDA(GPU)、ASML(露光装置)、TSMC(ファブ)、ARM(IP)です。
スタートアップ投資の観点では——アプリケーション層で「特定モデルに依存したビジネス」を作るのは危険。2026年だけでもGPT-5.4→Opus 4.7と2ヶ月で王座が入れ替わっているわけで、複数モデルを抽象化して切り替えられる設計のスタートアップが長期では生き残る、というのが私の仮説です。
公開市場の観点では、3社のラボ間競争が激化するほどNVDA・ASML・TSMCのGPU/ファブ系へのキャペックスは増える——つまり「誰が勝つか」を当てにいくよりも、「全員が走り続ける限り恩恵を受けるレイヤー」に寄せる方が、リスク調整後リターンは高くなる構造です。
- Claude/GPT/Geminiの次の主要バージョン — 王座交代が継続するか、誰かが固定的にリードを取るか
- NVDA決算のデータセンター売上 — モデル競争激化局面ではキャペックス連動性が高い
- OpenAI/Anthropicの一次資金調達バリュエーション — シードからの倍率が市場心理の温度計
- 規制動向(EU AI Act、米AI Bill of Rights実装) — 大規模モデル開発のコスト構造を変える
それでは、今回はここまで。皆さんの使い分けも教えてもらえると嬉しいです。
- 案1:数字で追う続編 — 本記事の前提を最新データで更新し、何が強まり、何が崩れたかを再点検する。
- 案2:実務テンプレート編 — 読者が自分の投資判断、制作単価、または開発運用に転用できるチェックリストへ落とし込む。
- 案3:反対シナリオの検証 — 今回の見立てが外れる条件を先に定義し、次に見るべき指標と時間軸を整理する。
本文の事実関係と数値前提は、再審査時にも読者が確認できる一次情報・公的資料を優先して見直しています。
本記事は情報提供を目的としたものであり、特定の銘柄、サービス、契約条件の推奨や投資助言ではありません。執筆者は記事内で触れた銘柄やサービスにポジションまたは利害関係を持つ可能性があります。調査、翻訳、校正の一部に生成AIを利用していますが、最終的な内容はZYL0が確認しています。詳細は免責事項をご確認ください。
Claude vs Gemini vs ChatGPT: A VC's Guide to the Latest Models
In the past two months, all three major AI labs have refreshed their flagships in rapid succession. OpenAI released GPT-5.4 (Pro / Thinking) on March 5, 2026. Anthropic shipped Claude Opus 4.7 on April 16. Google updated Gemini 3 to Gemini 3.1 Pro. These three are the current top tier.
As a VC who spends all day writing investment memos, summarizing earnings reports, and reading code with AI assistance, my honest take is: the era of "just use one model for everything" is over. Each flagship has sharpened its edges, and the differences matter in practice.
This article compares the three flagships as of April 2026, blending public benchmarks with real working-VC usage, and ends with my personal usage split.
A quick look back at the last two years:
GPT-4o was effectively the default in 2024. Multimodal was polished; "just subscribe to ChatGPT Plus" was the right answer.
Then Anthropic's Claude 3.5 Sonnet arrived with coding quality that clearly exceeded GPT-4o. Cursor, Cline, Aider — the AI coding tool ecosystem standardized on Claude almost overnight.
Gemini, frankly, was underwhelming in early 2024. Gemini 1.5's 1M-token context was interesting, but response quality lagged GPT-4 and Claude.
Reasoning was the 2025 theme. OpenAI shipped o1 → o3 → o4 in rapid succession. Anthropic added "Extended Thinking" to Claude 3.7 Sonnet. Google countered with Gemini 2.5 Pro's "Deep Think."
For math, science, and coding — problems with correct answers — every flagship reached PhD-level competence.
Now the current lineup:
- OpenAI: GPT-5.4 Pro (March 5, 2026)
- Anthropic: Claude Opus 4.7 (April 16, 2026)
- Google: Gemini 3.1 Pro (with Deep Think)
The major shift: users no longer toggle "reasoning mode" — the model decides. Simple questions are fast, hard ones take longer. That's the new normal.
Another trend: computer-use agents are now practical. GPT-5.4 scored 75% on OSWorld, beating human experts (72.4%). 2026 is the year AI actually started driving browsers and PCs.
Key benchmarks and real-world feel as of April 2026:
| Dimension | Claude Opus 4.7 | Gemini 3.1 Pro | GPT-5.4 Pro |
|---|
| Release date | April 16, 2026 | Early 2026 (3.1 gen) | March 5, 2026 |
| SWE-bench Verified | 87.6% | 80.6% | ~82% |
| SWE-bench Pro | 64.3% | ~53% | ~55–58% |
| GPQA Diamond (science) | high | 94.3% | high |
| Humanity's Last Exam | — | 44.4% | — |
| ARC-AGI-2 (abstract reasoning) | — | 77.1% | 83.3% |
| BrowseComp (web ops) | — | — | 89.3% |
| OSWorld (PC ops) | — | — | 75% |
| MMMU-Pro (multimodal) | ◯ | 80.5% | ◎ |
| Context length | 200K (1M variant) | 1M | 1M–1.1M |
| Input price ($/1M tokens) | $5 | ~1/5 of Claude | $2.50 |
| Output price ($/1M tokens) | $25 | lowest tier | $15 |
| Native video/audio | △ | ◎ | ◯ |
① Coding: Claude reclaims the crown
Opus 4.6 → 4.7 jumped SWE-bench Verified from 80.8% to 87.6%, a ~7-point gain that leapfrogs Gemini 3.1 Pro (80.6%) and GPT-5.4 (~82%). On the harder SWE-bench Pro, Opus 4.7 scores 64.3%, beating GPT-5.4 (~57.7%) and Gemini (~54.2%) by 10+ points.
CursorBench jumped 58% → 70%. In practice, "read this entire repo and point out the design flaws"-style prompts clearly land better on Claude.
② Science Reasoning: Gemini leads
GPQA Diamond 94.3% and MMMLU 92.6% put Gemini 3.1 Pro at the top of research-level knowledge and reasoning benchmarks. Google Research's foundational work shows up in rigor around symbolic math and paper comprehension.
③ Agentic / PC Control: GPT-5.4 dominates
BrowseComp 89.3% and OSWorld 75% (beats the 72.4% human expert baseline) make GPT-5.4 Pro the clear winner for "drive a browser and a PC" tasks. It also tops ARC-AGI-2 at 83.3% for abstract reasoning.
④ Long Context: Gemini's 1M wins on practicality
Claude offers a 1M context variant, but Gemini ships 1M as standard. For "dump 50 PDFs in one context" workloads, Gemini is the most cost-effective today.
⑤ Multimodal (video/audio): Gemini by design
Gemini was architected multimodal from day one — text, image, video, audio, code all unified. For summarizing a YouTube URL or turning long meeting recordings into minutes, Gemini is essentially the only choice.
⑥ Creative Writing: Claude still preferred
In blind human evaluations, Claude is picked 47% of the time vs. 29% for GPT-5.4 and 24% for Gemini. For investment memos and editorial drafts, Claude remains the safe choice.
⑦ Cost: Gemini crushes it
Gemini 3.1 Pro is roughly 1/5 of Claude Opus 4.7 and 1/4 of GPT-5.4. For batch processing and high-volume workloads, Gemini wins on pure economics.
Performance alone misses the "service + ecosystem" dimension.
- Strengths: Coding/agentic focus, creative writing, Artifacts, MCP ecosystem, top-tier finance-agent performance
- Weaknesses: No image generation, weaker video/audio than Gemini, highest API price ($5/$25)
- Platforms: Claude.ai, Claude Code (CLI), API, AWS Bedrock, Google Vertex AI
Anthropic is clearly developer-and-enterprise-first. Opus 4.7 is specifically tuned to "execute instructions literally where prior models interpreted them loosely" — prompt craft now matters more. Claude Code has become my primary IDE since its 2025 launch.
- Strengths: Google Search integration, Workspace (Gmail/Drive/Docs), native multimodal including video/audio, 1M context as standard, aggressively low pricing, strong science/math benchmarks
- Weaknesses: Coding polish still trails, less "first try" mindshare
- Platforms: gemini.google.com, AI Studio, Vertex AI, Google app integration, Gemini 3.1 Deep Think (Google AI Ultra subscribers)
Gemini's real advantage is Google ecosystem integration. Reading an entire corporate email inbox, cross-searching Drive docs — it dominates "daily work" surface area. Deep Think is a separate high-reasoning mode for science and engineering problems, switchable when you need it.
- Strengths: Agentic capability (BrowseComp/OSWorld dominant), abstract reasoning (ARC-AGI-2 83.3%), plugins/GPTs ecosystem, DALL-E/Sora integration, Advanced Voice Mode, Canvas, brand scale
- Weaknesses: Long time-to-first-token (reasoning model), knowledge cutoff August 2025
- Platforms: ChatGPT (web/app), API, Microsoft Copilot, Pro/Enterprise plans only
GPT-5.4 Pro is a class apart as a computer-use agent. Beating human experts on OSWorld is symbolic — for multi-step workflows like "research in browser → update spreadsheet → post to Slack," GPT-5.4 Pro is the top candidate. Voice mode remains best-in-class.
Here's how I actually divide my time across all three (yes, I pay for all three — business expense).
Use cases: Coding, earnings-report analysis, investment memos, contract review, creative/editorial drafts
- Drafted this article in Claude
- Maintain this Nuxt 3 blog via Claude Code
- Load 100+ PDFs in the 1M-context variant for due diligence
- SWE-bench Pro 64.3% translates directly into superior large-codebase comprehension
- "Execute instructions literally" tuning fits my workflow
Use cases: Research, Google Workspace integration, video/audio, multilingual translation, high-volume batch
- Full conference recordings → key-point extraction
- Sorting mixed EN/JA/ZH pitch emails from my corporate inbox
- Latest-info research with Google Search grounding
- Absurdly cheap — my volume workhorse
- Deep Think for DD on science/deep-tech startups
Use cases: Web automation, image generation, voice, brainstorming, custom GPTs
- BrowseComp strength shines on "crawl 10 IR pages and extract earnings data"
- OSWorld strength means I can trust it to fill Excel/Sheets automatically
- Visuals for portfolio-company decks (DALL-E/Sora)
- Voice brainstorming while walking
- Founders still say "I tried it on ChatGPT…" — I need it for verification
The "model war" is over. We're in the "specialization" phase. April 2026 boils down to this:
- Coding / long context / creative → Claude Opus 4.7
- Science / multimodal / volume / cost → Gemini 3.1 Pro
- Web+PC automation / abstract reasoning / ecosystem → GPT-5.4 Pro
One piece of VC advice: don't skimp on $20–30/month × 3 subscriptions. Workloads differ, and using them appropriately massively improves productivity.
This is where the piece earns its VC framing. The investor question isn't "which model wins?" — it's "how does the back-and-forth between the three labs ripple through related stocks?".
| Scenario | Probability | OpenAI/MSFT | Anthropic (AMZN/GOOGL bet) | Google/GOOGL | NVDA |
|---|
| A. Three-way continues (base) | 50% | Neutral | Neutral | Slight upside | Core |
| B. Anthropic pulls ahead (Claude coding dominance) | 25% | Neutral | Upgrade | Neutral | Core |
| C. Google reverses (Gemini ecosystem integration wins) | 15% | Slight down | Neutral | Upgrade | Core |
| D. OpenAI agentic dominance | 10% | Upgrade | Neutral | Neutral | Core |
My current base case is A: the next ~12 months stay competitive, with leadership flipping between the three. From the CVC seat, the most useful position in this kind of regime is "benefits no matter who wins" — concretely NVDA (GPUs), ASML (lithography), TSMC (fab), ARM (IP).
For startup investors: building application-layer businesses that depend on a single model is dangerous. Just in 2026, the crown flipped from GPT-5.4 to Opus 4.7 in two months. Startups that abstract over multiple models and swap them transparently will be the ones that survive the next two crown flips.
For public markets: the more intense the competition between the three labs, the more capex flows into NVDA/ASML/TSMC. Trying to pick which lab wins is a worse risk-adjusted bet than positioning across the layer that benefits while everyone keeps running.
- Next major versions of Claude / GPT / Gemini — does the crown keep flipping, or does someone consolidate the lead?
- NVDA earnings, datacenter segment — high beta to lab competition intensity
- OpenAI / Anthropic primary fundraising valuations — markup multiples are the temperature gauge
- Regulation (EU AI Act, US AI Bill of Rights implementation) — changes the cost structure of frontier model development
That's all for today. I'd love to hear how you split your usage.
- Idea 1: A data-updated follow-up — Revisit the thesis with fresh numbers and separate what strengthened from what broke.
- Idea 2: A practical template edition — Turn the article into a checklist readers can reuse for investing, pricing, or technical operations.
- Idea 3: The bear-case test — Define the conditions that would invalidate this view and map the indicators to watch next.
The factual and numerical assumptions in this article are anchored to primary or public materials that readers can revisit during AdSense review and future updates.
This article is for informational purposes only and does not constitute investment advice or a recommendation of any specific stock, service, or contract structure. The author may hold positions or interests related to companies or services mentioned. Generative AI was used for parts of research, translation, and proofreading, with final review by ZYL0. See the disclaimer for details.