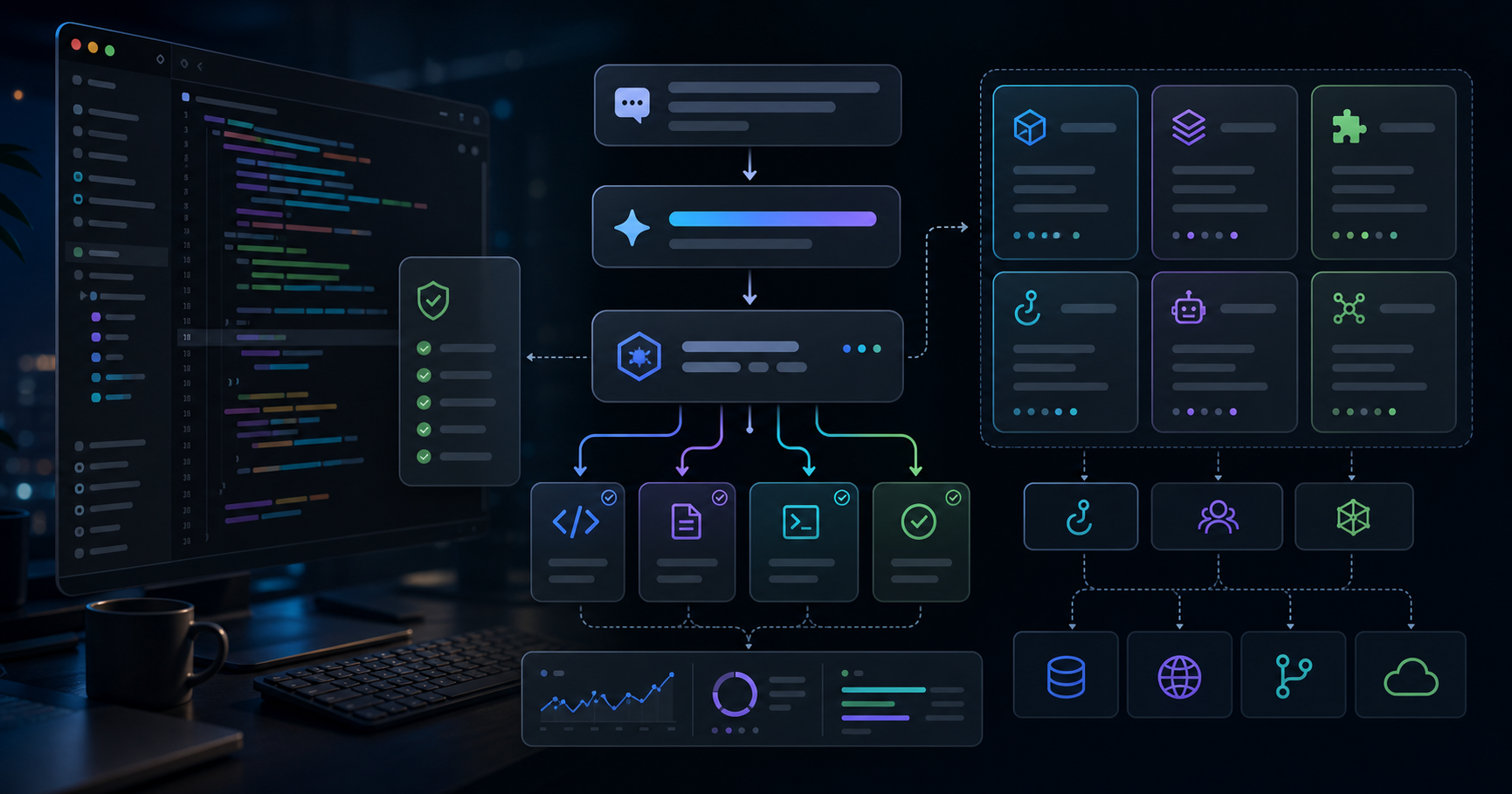
AIエージェントを「組織」として回す設計思想:12体のサブエージェントとNeon × Prismaタスクボードで作る一人会社のアーキテクチャ
バージョン注記: 本記事は2026年5月時点の運用ログを基にしている。Claude Code v2系、Claude Sonnet 4.6 / Haiku 4.5、Next.js 14・Prisma 5・Neon serverless Postgres + pgvector 0.7、Vercel runtime を前提としている。
.claude/agents/
のサブエージェント機能と SessionStart / PreToolUse の2つのフックを使う構成だ。モデル仕様、Claude Code のフック仕様、Neon の料金プランは変動するので、最新は公式ドキュメントを参照してほしい。
私はもともと半導体プロセス開発のエンジニアで、その後CVCのキャピタリストに転身した。投資チームに加わって最初にぶつかったのは「DDの品質基準が人によってバラバラ」という問題で、これを3ヶ月で標準化したときに痛感したのは「品質は個人の頑張りではなく仕組みで担保するもの」という当たり前の事実だ。この同じ実感が、Claude Code のサブエージェントを 500 時間ぶん回した結果、ほぼそのまま再現された。 今回はその運用設計を、コード・スキーマ・Neon の活用箇所まで隠さずに書く。
| テーマ | 学べること |
|---|
| 一人AI vs 組織化AI | なぜチャット1画面の運用には天井が来るのか、構造的な3つの理由 |
| 組織の4要素 | 投資チーム運営から借りた「専門化・レビュー・書き物・責任明示」のサブエージェントへの応用 |
| 12体の役割分担 | Leadership / Engineering / Quality / Content・Strategy・Legal の4グループの境界 |
| 実装スタック | Next.js + Prisma + Neon(serverless Postgres + pgvector) + pnpm task CLI + knowledge/ Obsidian互換vault |
| Neon活用の核 | ブランチでDBレベルのgit、PITRでInbox削除事件の保険、pgvectorで意味検索、suspend-on-idleで24/7運用の経済成立 |
| 落とし穴 | Inboxノートを勝手に削除された事故と、Decision Boundariesによる回避策、Vercel + Neon でのコネクション管理 |
最初に断っておくと、AIエージェントの議論はいまだに**「もっと賢いモデルが出れば解決する」という発想に引きずられすぎている**ように見える。Claudeがいい、いやGPTのほうが、Codexのコーディング性能が——という比較は健全だが、その全部が「一つのAIに全部やらせる」前提で語られている点に問題がある。
実際に私が1日6時間以上、3ヶ月にわたってClaude Codeをぶん回した結果、この前提には3つの構造的な天井が見えた。
1. 文脈が混ざると出力がブレる。 プロジェクトAの仕様、クライアントBの要件、先週の会議メモ、今日の買い物リストを同じセッションに突っ込むと、関係ない情報がノイズとなって回答が歪む。これは半導体プロセスのTCADシミュレーションで「境界条件を一つ間違えるだけで結果が桁単位でズレる」のと構造的に同じだ。
2. ハルシネーションが増える。 文脈が散らかっていると、AIは「先週こう決まりましたよね」と決まってもいないことを断言する。投資先のDDで現場担当者が「装置の問題」と自信満々に報告してきた収率不良が、実はTCADで再シミュレーションすると製造プロセス側の境界条件にあった、というのと似ている。自信満々の誤報告は、複数のレンズを通さないと検出できない。
3. レビュアーがいない。 一つのAIだけだと、出力をチェックする責任は人間(=私)一人に集中する。プロンプトを書き、結果を読み、判断する——これは投資委員会を経ない単独投資判断と同じで、まともな現場ではあり得ない動かし方だ。Googleでもどこのまともな現場でも、デザインレビュー・コードレビュー・ローンチレビューがあって、品質は仕組みで担保されている。
問題は、この3つを「組織化」で同時に解く方法が、まだあまり共有されていないことだ。
私が3ヶ月で投資チームのDD標準化を回したとき、出来上がった仕組みには4つの柱があった。これがそのまま、Claude Codeサブエージェントの組織設計に転用できると気づいた瞬間が、この運用の起点になっている。
| 要素 | 投資チームでの実装 | サブエージェントでの実装 |
|---|
| 専門化 | 市場/技術/財務/法務でDD領域を分担 | 12体を4グループに分割(後述) |
| レビュー文化 | 投資委員会で複数のレンズを通す | qa-reviewer / brand-voice-reviewer / anti-ai-slop-reviewer の三段レビュー |
| 書き物で引き継ぐ | 投資メモ・ADR・PRD | knowledge/handoffs/ への必須ハンドオフノート |
| 責任の所在を明示 | 担当者裁量 / マネージャー裁量 / 委員会裁量 | decision-boundaries.md で「Agentが決めていいこと/エスカレートすべきこと/Hard Stop」を明文化 |
正直、最初は「こんなの当たり前じゃないか」と自分でも思っていた。でも実際にサブエージェントに当てはめてみると、人間の組織が数千年かけて試行錯誤で辿り着いた答えが、ほぼそのまま効くことがわかった。情報の共有・判断の分散・質の担保・決裁の経路——複数のサブエージェントを走らせると、この4つの問題がそっくり再発する。だったら歴史の答えを借りるのが合理的、というのが私の現時点の結論だ。
ここからは私が実際に運用しているシステムを、できる範囲で正直に書く。動画やデモのために作ったモックではなく、ZYL0 Labの実業務(ブログ執筆・コード開発・投資分析・契約書一次レビュー)を実際に回している現役のシステムだ。スタックはあえて贅沢にせず、一人で保守できる範囲に絞っている。
┌────────────────────────────────────┐
│ knowledge/ (Markdown vault) │
│ context, projects, decisions, │
│ handoffs, playbooks, inbox │
└────────────────────────────────────┘
▲ ▲
read/write │ │ read/write
│ │
┌───────────┐ ┌────────┴────────┐ ┌─────────┴────────┐
│ Browser │ ◄►│ Next.js (App) │ │ Claude Code │
│ /board │ │ src/app/ │ │ 12 subagents │
│ /knowledge│ │ server actions │ │ skills + hooks │
└───────────┘ └────────┬────────┘ └────────┬─────────┘
│ Prisma │ Bash → CLI
▼ ▼
┌────────────────┐ ┌──────────────────┐
│ src/lib/ │ ◄──│ scripts/cli/ │
│ tasks.ts │ │ task.ts │
│ views.ts │ │ note.ts │
│ embeddings.ts│ │ │
└────────┬───────┘ └──────────────────┘
▼
┌────────────────────────────────────┐
│ Neon (serverless Postgres) │
│ branches: main / preview-* / │
│ recover-* + pgvector for │
│ handoff embeddings │
└────────────────────────────────────┘
設計上の重要な選択は4つある。まず、CLIがHTTPを介さずPrismaクライアントを直接共有している点。サブエージェントは
pnpm task add ...
を Bash で叩いてボードを操作するが、UI のサーバーアクション・REST ルート・CLI のすべてが
src/lib/tasks.ts
の
validateTaskCreate
/
validateTaskUpdate
を通る。検証面は1つだけ、というのは半導体プロセスでも同じで、「同じ検査仕様を複数の経路で持つと必ず仕様乖離が起きる」という教訓がある。
次に、Markdown vault が knowledge/
という repo ルート直下にあること。 これは Obsidian でリポジトリをそのまま vault として開けるようにするための配置だ。サブエージェントは
src/lib/knowledge.ts
経由で読み書きし、
KNOWLEDGE_ROOT
の外に escape できないようパスを sandbox している。
3つ目に、Claude Code の hooks を .claude/settings.json
に直書きせず TS スクリプトで持っている。 SessionStart で P0 タスク・Blocked・Stale を取得して標準出力に流し込み、PreToolUse(matcher: Task)でサブエージェントごとのロールリマインダーを差し込む。フック本体が TypeScript なので Prisma クライアントと UI 用 view 関数をそのまま使えるのが効いた。
そして4つ目が、DBを Neon の serverless Postgres に固定し、ローカル開発も SQLite ではなく Neon の dev ブランチを使うこと。SQLite ローカル+本番 Postgres という構成は便利に見えて、列の挙動・JSONBのインデックス・トランザクション分離レベルがズレるので、結局本番でしか出ない不具合を生む。「検証面は1つだけ」の原則を DB にも適用した格好だ。
DATABASE_URL
は Neon の pooled endpoint、
DIRECT_URL
は direct endpoint で、後者は
prisma migrate
専用に分けている。
ここからが今回の追加分だ。SQLite から Neon serverless Postgres に切り替えたのは、見栄えのためではなく、サブエージェント運用の弱点をピンポイントで埋める4つの具体的な理由があった。正直に言うと、一人会社にDB分岐は過剰だろうと最初は思っていた。Neon のブランチ機能は、結果的にこのスタックで一番使う安全装置になった——これは運用してみて初めて腹落ちした感覚だ。
サブエージェントがスキーマを触る系のタスク(マイグレーション、列追加、インデックス調整)を実行するとき、本番DBに直接触らせるのは怖い。Neon の branch は数秒で生成できる完全独立のDBで、本番のデータ形を持ったまま実験できる。
# 本番(main)から派生したブランチを作り、そのDATABASE_URLをエージェントに渡す
neonctl branches create --name preview/agent-add-tags-col --parent main
neonctl connection-string preview/agent-add-tags-col --pooled
# エージェントはブランチ側で migrate
prisma migrate dev --name add_tags_col
# レビューOKならmainに再apply、NGならブランチを破棄して終了
neonctl branches delete preview/agent-add-tags-col
backend-engineer の Decision Boundaries には「prod ブランチへ直接 schema push 禁止、必ず preview ブランチ経由」と書いてある。これは git の「main への直 push 禁止」と構造的に同じ規律で、AI に裁量を渡すときの最低ラインになる。
教訓2で書いた Inbox の一括削除事件、当時は SQLite のスナップショットを手動で取っていただけだった。Neon の Point-in-Time Restore は秒単位で過去に戻れる(プランによるが最大30日保持)。事故の5分前から新しいブランチを切って、消された行だけ戻せばいい。
neonctl branches create \
--name recover/inbox-2026-05-03 \
--parent main \
--timestamp "2026-05-03T03:14:00Z"
「不可逆なミス」が「5分のロールバック」に変わると、エージェントに任せられる作業の心理的閾値が一段下がる。これは数字で測りにくい効果で、運用してみて初めてわかった。
handoffs/
や
decisions/
が増えてくると、ファイル名検索だけでは「あの時のADR、どこだっけ」が引き出せなくなる。Neon は pgvector 拡張をネイティブで動かせるので、handoff/ADR のテキストを Embedding して同じDBに置いている。
// src/lib/embeddings.ts
import { prisma } from './db'
import { embed } from './embedder'
export async function searchHandoffs(query: string, k = 5) {
const [{ embedding }] = await embed([query])
// pgvector のコサイン距離で近傍検索
return prisma.$queryRaw<
Array<{
taskId: string
slug: string
similarity: number
}>
>`
SELECT "taskId", "slug",
1 - ("embedding" <=> ${embedding}::vector) AS similarity
FROM "HandoffEmbedding"
ORDER BY "embedding" <=> ${embedding}::vector
LIMIT ${k};
`
}
ファイル名引きは既知IDが分かっているとき用、pgvector は「なんとなく似た過去案件」を引きずり出すとき用、と役割を分けている。サブエージェントが
searchHandoffs("似た意思決定の前例")
を呼ぶだけで意味的に近いノートが返ってくるので、ハンドオフが「書きっぱなし」にならない。
教訓1の「不可能だった仕事の経済的成立」と直接つながる話だ。Neon の compute は一定時間アイドルだと自動的に suspend し、課金が止まる。実際、夜間 QA は1時間あたり2〜3分しか走らないので、24/7 体制でも月額は数ドルレベルに収まっている。
24時間動く組織を、サーバ代を気にせず一人で持てる——これが Vercel + Neon の組み合わせで一番効いた箇所だった。
サブエージェントは現在12体で、
.claude/agents/<role>.md
に YAML frontmatter で description を書いている。ここの
description
文が Claude Code のルーターを兼ねるので、「Use when…」「Do not invoke for…」を具体的に書くのが肝になる。
| グループ | エージェント | モデル | 主な責務 |
|---|
| Leadership / Routing | engineering-lead / business-director / task-dispatcher | sonnet / sonnet / haiku | 仕事の分解とルーティング、優先順位付け |
| Engineering | frontend-engineer / backend-engineer / infra-ops | sonnet / sonnet / haiku | UI実装 / スキーマ・API・CLI / ボード衛生・夜間ジョブ |
| Quality | qa-reviewer / brand-voice-reviewer / anti-ai-slop-reviewer | sonnet / haiku / haiku | 受け入れ基準検証 / ブランド準拠 / AIっぽさ検出 |
| Content / Strategy / Legal | content-director / legal-first-pass / morning-standup-writer | sonnet / sonnet / haiku | 長文構成 / 契約書一次レビュー / 朝のブリーフ |
ルーティングの基本動作はこうなる。
operator note → task-dispatcher → specialist
↘ engineering-lead (engineering, complex)
↘ business-director (strategy)
engineer finishes → qa-reviewer → Done
↘ back to engineer (FAIL)
content draft → content-director → brand-voice-reviewer
↘ anti-ai-slop-reviewer
contract → legal-first-pass → operator (always)
モデル選択は単純で、複数ファイル文脈で判断するロール(エンジニアリング・コンテンツ・QA・法務)はSonnet、プロンプトが思考の大半を担うルール検出系(slopチェック・voiceチェック・dispatcher・infra衛生・morning brief)はHaikuにしている。Opusはあえて常設していない。 戦略判断が必要な場面はオペレーター(私)が拾うか、ADR を起こす運用に倒したほうが、コストも責任所在もクリーンになった。
backend-engineer の定義はこんな感じだ。description を「ルーターのスイッチ」として書くのが一番大事で、ここが曖昧だと task-dispatcher がどこに振っていいかわからなくなる。
---
name: backend-engineer
description: >
Use when the task touches src/lib/, prisma/schema.prisma, server actions,
API routes under src/app/api/, scripts/jobs/, or scripts/cli/. Do not
invoke for UI changes (use frontend-engineer) or stale-board hygiene
(use infra-ops).
model: sonnet
tools: [Read, Write, Edit, Bash, Glob, Grep]
---
# Backend Engineer
## Scope
- Prisma schema and migrations (always on a Neon preview branch first)
- Validation helpers in src/lib/tasks.ts
- Server actions and API routes
- Job scripts in scripts/jobs/
## Workflow
1. Read the task and acceptanceCriteria from the board
2. Implement minimum viable change; do not refactor unrelated code
3. Add a regression test or CLI invocation that proves the change
4. Move task to Review with a one-line summary in handoffNote
## Don'ts
- Never run prisma migrate reset
- Never push schema directly to the Neon prod branch (use a preview branch)
- Never add a dependency without an ADR
- Never edit .claude/agents/\* — escalate to operator
ポイントは description 末尾の「Do not invoke for…」だ。これがないと task-dispatcher が UI 関連まで backend-engineer に振ってしまうことが現実に起きる。「やってはいけないこと」を裁量境界として明文化する——これは投資チームのDD標準化で口酸っぱく言ってきたことと完全に同じだ。
ボードのコアは Prisma の単一
Task
テーブルで、Neon Postgres の上に乗っている。列挙型は Postgres の native enum に上げず、ローカルのモック・テストで扱いやすい string のままにしている。
auditTrail
は Postgres ネイティブの JSONB に置けるので、SQLite 時代のように JSON 文字列としてシリアライズせず、
auditTrail @> '[{"event":"deleted"}]'::jsonb
のような部分一致クエリが直接書ける。
// src/lib/types.ts
export const STATUSES = [
'Inbox',
'Unassigned',
'InProgress',
'Blocked',
'Review',
'Done',
'Archived',
] as const
export const PRIORITIES = ['P0', 'P1', 'P2', 'P3'] as const
export const TEAMS = ['engineering', 'content', 'business', 'infra', 'human'] as const
export type AuditEntry = {
ts: string
actor: string // "agent:backend-engineer" or "human:operator"
event: string // e.g. "status:InProgress->Review"
detail?: string
}
Neon 側に固有な部分は Prisma スキーマに出る:
// prisma/schema.prisma — Neon-specific bits
generator client {
provider = "prisma-client-js"
previewFeatures = ["postgresqlExtensions"]
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL") // Neon pooled
directUrl = env("DIRECT_URL") // Neon direct (for migrate)
extensions = [pgvector]
}
model Task {
id String @id @default(cuid())
status String
priority String
team String
auditTrail Json // Postgres JSONB — supports @> partial match
// ...
}
model HandoffEmbedding {
taskId String @id
slug String
embedding Unsupported("vector(1536)")?
createdAt DateTime @default(now())
}
状態遷移は表で見たほうが早い。Review→Done では
handoffNote
を
警告レベルで要求している点がポイントだ。エラーで弾くと「とりあえず空文字を入れて通す」という回避が起きるので、ブロックせず警告として浮上させる設計にしている。
| From → To | 必須 | 監査イベント | 副作用 |
|---|
| new → Inbox | title, description, createdBy | created | auditTrail 初期化 |
| InProgress → Blocked | blockerReason | status:InProgress->Blocked | — |
| InProgress → Review | acceptanceCriteria | status:InProgress->Review | qa-reviewer が自動拾い上げ |
| Review → Done | handoffNote (推奨) | status:Review->Done | completedAt セット |
| any → Archived | — | archived | listTasks から除外 |
削除は UI / CLI からは不可能にした。これは事故防止の意味でかなり効いている(後述)。本当に消したい場合は
prisma studio
をオペレーター(=私)が手動で開く。
knowledge/
は repo ルート直下のフォルダで、Obsidian でそのまま vault として開ける。サブエージェント同士は
リアルタイムに会話しない。代わりに、ここにファイルを書いて引き継ぐ。
knowledge/
├── inbox/ # ブレインダンプ・夜間スナップショット・朝のブリーフ
├── projects/ # プロジェクト単位のブリーフ
├── ideas/ # まだプロジェクト化していない発想
├── resources/ # 参考資料
├── context/ # 哲学・identity・voice・strategy・boundaries
├── handoffs/ # <task-id>-<slug>.md 形式の引き継ぎノート
├── decisions/ # 連番ADR
└── playbooks/ # nightly-qa など反復手順
特に重要なのが
context/
と
handoffs/
の2つだ。
context/
には philosophy / professional-identity / visual-design-language / product-strategy / decision-boundaries が並んでいる。これらが全エージェントに「ZYL0 Lab とは何か」を常時供給する共有記憶になる。
handoffs/
のファイル名は
<task-id>-<slug>.md
という規約にしてあるので、
pnpm task show <id>
と
ls knowledge/handoffs/<id>-*.md
の双方向引きが効く。
ファイル名引きで足りない「意味で似た過去ノート」は、Neon 上の pgvector 経由で searchHandoffs
を叩く——Neon を導入した理由3そのままで、ファイル系と意味系の二層検索が同じDBにまとまっているのは想像以上に楽だった。
AWSでIoT Coreの非同期メッセージングを設計したとき、「リアルタイム同期は壊れやすく、非同期キュー+永続ログは壊れにくい」という感覚を強く持った。サブエージェント運用でもまったく同じで、ハンドオフをチャットではなくファイルに落とすだけでデバッグ可能性が桁違いに上がる。
12体のサブエージェントを動かしていて一番効いたのが、
knowledge/context/decision-boundaries.md
を最初に書き切ったことだ。3つの領域で線を引いている。
Agentが自分で決めていい
- 自分のタスク内のファイル単位リファクタ
- テスト追加
- 既存フォルダ内のノート再整理
- より適切なサブエージェントへの再アサイン(監査記録あり)
- 独立検証後の
Review
マーク
オペレーターにエスカレートする
prisma/schema.prisma
のスキーマ変更package.json
への依存追加.claude/settings.json
・ .claude/agents/*
・ .claude/skills/*
・ CLAUDE.md
の変更- クラウド/外部システムに触る操作
- ADR 級の判断
Blocked
への遷移
Hard Stops(オペレーター明示確認なしには絶対に実行しない)
git push --force
prisma migrate reset
rm -rf
pnpm prune
- 他エージェントが進行中のタスクの archive
knowledge/decisions/
の編集(追記のみ)- Neon prod ブランチへの直接 schema push(必ず preview ブランチ経由)
エスカレーションのメカニズムもコード化してある。サブエージェントはタスクを
Unassigned
に戻し、フィールドを次のように埋める。
assigneeType
= human
assigneeId
= operator
- 優先度を設定
handoffNote
に質問を書き込む
すると私の
/board/needs-attention
ビューが自動的にそれを拾う。
ここからが今日一番書きたかった部分だ。500 時間のオペレーター直接稼働、無人稼働を含めて 1000 時間級ぶん回して、私が本当に大事だと思うようになったのは次の3つだ。
夜中に動くQA、knowledge/ のゴミ掃除、stale-checkジョブ——これらは個人プレイヤーでは経済的に成立しない仕事だ。一人だと割に合わないので、普通はやらない。でも自律的に動くサブエージェントがいれば、追加の人件費なしで 24 時間動かせる。結果として「シリコンバレーのまともな現場と同じ品質管理」が、一人事業の規模で初めて手に入る——これが私には一番効いた。時間節約ではなく「不可能だった仕事の経済的成立」が、組織化AIの本当の価値だと現時点では考えている。そして Neon の suspend-on-idle と Vercel のサーバレス課金がここに直接効く——アイドル時間にコストが発生しないから、24/7 シフトを一人で持てる経済が成立した。
人間の新人なら「Inboxを勝手に消したら怒られそう」と察してくれる。サブエージェントは察してくれない。「消すな」と書いていなければ、消す可能性がある。 これは比喩ではなく、私のknowledge/で実際に起きた。あるエージェントが「整理しておきます」と言って Inbox の未処理ノートをまとめて削除したのだ。
ここから学んだのは、判断基準は全部書き下す必要があるということ。今は「Tasks: deletion is not supported via UI/CLI」「Knowledge: handoffs/ は decision boundaries により削除禁止」を明文化し、UI と CLI からは archive しか提供していない。投資チームのDD標準化のときも全く同じで、「常識でわかるだろう」と省略した部分が必ず事故を生んだ。補足すると、Neon に移してから PITR が「不可逆な事故」を「5分のロールバック」に変えた。記述による予防が第一線、Neon のリストアが第二線、という二重構造になっている。
これが一番怖い教訓だ。サブエージェント組織は、エラーも警告も出さずに壊れる。 設定ファイルが壊れていても「書き込み完了しました」と返事して次の仕事に移る。タスクボードのキューが詰まっても「処理中です」と表示し続ける。
人間の新人なら「このメッセージ届いてないんですけど?」とエスカレーションしてくれるが、AIはしない。だから**「動いてます」報告だけでは絶対に足りない**。今は morning-standup-writer が毎朝、夜間スナップショット+今日のフォーカス+エディター注釈を
knowledge/inbox/morning-brief-latest.md
に書く。私はこれを開けば 3 分で全体の健康診断ができる。観察可能性(observability)はサブエージェント運用の必須要件だと言い切れる。
特に頻度が高かったハマりポイントを共有する。
罠1: description が曖昧でルーターが詰まる。 「Use when engineering tasks」みたいな広すぎる description だと、task-dispatcher が UI も schema も infra hygiene も全部 backend-engineer に振る。回避策は description を**「Use when X. Do not invoke for Y.」の対称形**で書くこと。Don't 側が Router の精度を上げる。
罠2: 検証ロジックが分散する。 UI のサーバーアクション、REST ルート、CLI で別々に validation を書くと、必ず仕様乖離が起きる。回避策は
validateTaskCreate
と
validateTaskUpdate
を
src/lib/tasks.ts
の単一 export として持ち、3経路すべてがそれを通す設計にすること。CLI と UI が
同じ Prisma クライアントを共有しているからこそ成立する。
罠3: タスクボードが腐る。 完了したのに
status
が
InProgress
のまま放置されるタスクが、数日で数十件溜まる。回避策は
scripts/jobs/stale-check.ts
を夜間に走らせる方式だ。
updatedAt
が 72 時間以上前の非 Done / 非 Archived タスクを
stale
タグでマークする。ただし
自動 archive はしない——infra-ops は「これは stale に見える」とオペレーターに提案するだけで、最終判断は人間に残す。
罠4: AIっぽい文章が混ざる。 content-director だけだと、どうしても「いかがでしたか」的な表現や em-dash padding が混ざる。回避策が anti-ai-slop-reviewer を最終チェックに置くこと。これは私が普段絶対書かないフレーズリストをマニュアルに持っていて、検出したら強制的に書き直しを要求する。
罠5: Vercel + Neon でのコネクション管理。 Vercel のサーバレス関数は呼び出しごとに新しい接続を張るので、Neon に対してすぐに接続上限が見える。回避策はシンプルで、
DATABASE_URL
には Neon の
pooled endpoint を
?pgbouncer=true&connection_limit=1
付きで使い、
DIRECT_URL
には direct endpoint を割り当てて
prisma migrate
専用にする。Edge runtime で動かしたいルートだけ
@neondatabase/serverless
の HTTP/WebSocket ドライバに切り替える、という3経路の使い分けが今のところ一番安定している。Prisma の Data Proxy を使う手もあるが、CLI と UI で同じクライアントを共有する設計と相性が悪く、今は採用していない。
500時間オペレーター稼働、累計1000時間級でこの仕組みを回した結論は、当初の予想よりずっとシンプルだった。
この4つは、私がCVCで投資チームを標準化したときの方法論とほぼ同じだ。AIだから特別な原則が必要、ということはない。人間の組織が長い時間をかけて見つけてきた答えに、AIならではの強み(24時間稼働・コスト最適化・並列実行)を足す——これが現時点で私の見ている景色だ。
どのモデルが強いかで議論するのは表面的な勝負で、どう回すかで本当の差がつく。Claude でも Gemini でも GPT でも、Prisma のテーブルと knowledge vault を中心に据える設計思想は同じように適用できる。そしてその「Prisma のテーブル」を Neon の上に置いた瞬間、ブランチ・PITR・pgvector・suspend-on-idle という4つの装備が一気に手に入る。12体のサブエージェントを本番DBに対して安心して走らせられるのは、この組み合わせの成果だ。
- 案1:数字で追う続編 — 本記事の前提を最新データで更新し、何が強まり、何が崩れたかを再点検する。
- 案2:実務テンプレート編 — 読者が自分の投資判断、制作単価、または開発運用に転用できるチェックリストへ落とし込む。
- 案3:反対シナリオの検証 — 今回の見立てが外れる条件を先に定義し、次に見るべき指標と時間軸を整理する。
本文の事実関係と数値前提は、再審査時にも読者が確認できる一次情報・公的資料を優先して見直しています。
本記事は情報提供を目的としたものであり、特定の銘柄、サービス、契約条件の推奨や投資助言ではありません。執筆者は記事内で触れた銘柄やサービスにポジションまたは利害関係を持つ可能性があります。調査、翻訳、校正の一部に生成AIを利用していますが、最終的な内容はZYL0が確認しています。詳細は免責事項をご確認ください。
Running AI Agents as an Organization: A 12-Subagent, Neon-Backed Postgres Task Board Architecture for a One-Person Company
Version note: Based on operational logs as of May 2026. Assumes Claude Code v2.x, Claude Sonnet 4.6 / Haiku 4.5, Next.js 14, Prisma 5, Neon serverless Postgres + pgvector 0.7, and Vercel runtime. Uses
.claude/agents/
for subagents and two Claude Code hooks (SessionStart and PreToolUse). Model specs, Claude Code hook specs, and Neon pricing tiers move fast — check official docs for current behavior.
I started out as a semiconductor process development engineer and later moved into venture capital as a CVC investor. The first thing I ran into when I joined the investment team was that "DD quality standards varied wildly between people." When I led the standardization effort over three months, the lesson that stuck was the obvious one: quality is guaranteed by structure, not by individual effort. That same realization came back, almost word-for-word, after I spent 500 hours running Claude Code subagents (closer to 1,000 if you count unattended runtime). This post is the operational design I arrived at — written at the code, schema, and Neon-utilization level, with nothing hidden.
| Topic | What you'll learn |
|---|
| Single AI vs. organized AI | Three structural reasons a single chat-window setup hits a ceiling |
| Four organizational pillars | How "specialization, review, written handoff, clear ownership" from VC team ops translate to subagents |
| The 12-agent breakdown | Boundaries between Leadership / Engineering / Quality / Content-Strategy-Legal |
| Implementation stack | Next.js + Prisma + Neon (serverless Postgres + pgvector) + pnpm task CLI + an Obsidian-compatible knowledge/ vault |
| Why Neon (the core wins) | Branching as DB-level git, PITR as the Inbox-deletion safety net, pgvector for semantic recall, suspend-on-idle as the economic enabler |
| Pitfalls | The Inbox-deletion incident, Decision Boundaries as the antidote, Vercel + Neon connection management |
Discussions about AI agent operations still feel too anchored on "a smarter model will solve it," at least to me. Comparing Claude vs. GPT vs. Codex is fair, but every one of those debates assumes a single AI doing the entire job. That assumption, I think, is where the wheels come off.
After three months of running Claude Code 6+ hours a day, I see three structural ceilings to that approach.
1. Mixed context warps output. When you stuff Project A's spec, Client B's requirements, last week's meeting notes, and today's grocery list into the same session, irrelevant signal becomes noise and answers drift. It's structurally identical to running a TCAD process simulation where one wrong boundary condition shifts the result by an order of magnitude.
2. Hallucinations multiply. With cluttered context, the AI confidently asserts things that were never decided. I'm reminded of a yield issue at a portfolio company that the field engineer "confidently reported" as an equipment problem — when I re-ran the TCAD simulation, the actual root cause was a process-side boundary condition. Confidently wrong reports cannot be caught without multiple lenses.
3. There is no reviewer. With a single AI, the responsibility to check output collapses onto one human (me). I write the prompt, I read the result, I judge — that's a sole-investor decision with no investment committee, and no serious shop runs that way.
The unsolved part is how to address all three at once through "organization."
When I led the DD standardization at the investment team, the structure that emerged had four pillars. The moment I realized those same four pillars map cleanly onto Claude Code subagents was where this whole operation began.
| Pillar | Investment team | Subagent org |
|---|
| Specialization | DD split by market / tech / finance / legal | 12 agents across 4 functional groups (below) |
| Review culture | Investment committee runs multiple lenses | qa-reviewer / brand-voice-reviewer / anti-ai-slop-reviewer in series |
| Written handoff | Investment memos, ADRs, PRDs | Mandatory knowledge/handoffs/ notes per task |
| Clear ownership | Analyst / manager / committee authority | decision-boundaries.md codifies "agent decides / escalate / hard stop" |
Honestly, I thought "this is just common sense" at first. But mapping it onto subagents, I found that the answers human organizations spent millennia evolving carry over almost intact. Information sharing, decision distribution, quality assurance, escalation paths — when you run multiple subagents, the exact same four problems resurface. So borrowing the historical answer is the rational move, at least where I currently stand.
From here I'll describe the system I actually use — not a demo mock, but the live setup that runs ZYL0 Lab's real work (blog drafting, code, investment analysis, first-pass contract review). The stack is deliberately not flashy; everything has to be maintainable by one person.
┌────────────────────────────────────┐
│ knowledge/ (Markdown vault) │
│ context, projects, decisions, │
│ handoffs, playbooks, inbox │
└────────────────────────────────────┘
▲ ▲
read/write │ │ read/write
│ │
┌───────────┐ ┌────────┴────────┐ ┌─────────┴────────┐
│ Browser │ ◄►│ Next.js (App) │ │ Claude Code │
│ /board │ │ src/app/ │ │ 12 subagents │
│ /knowledge│ │ server actions │ │ skills + hooks │
└───────────┘ └────────┬────────┘ └────────┬─────────┘
│ Prisma │ Bash → CLI
▼ ▼
┌────────────────┐ ┌──────────────────┐
│ src/lib/ │ ◄──│ scripts/cli/ │
│ tasks.ts │ │ task.ts │
│ views.ts │ │ note.ts │
│ embeddings.ts│ │ │
└────────┬───────┘ └──────────────────┘
▼
┌────────────────────────────────────┐
│ Neon (serverless Postgres) │
│ branches: main / preview-* / │
│ recover-* + pgvector for │
│ handoff embeddings │
└────────────────────────────────────┘
Four design choices stand out. First, the CLI shares the Prisma client directly instead of going through HTTP. Subagents manipulate the board by running
pnpm task add ...
from Bash, but UI server actions, REST routes, and the CLI all funnel through
validateTaskCreate
/
validateTaskUpdate
in
src/lib/tasks.ts
. One validation surface, period. The semiconductor world has a similar law: keep the same inspection spec across multiple test paths or your spec will silently diverge.
Second, the Markdown vault sits at the repo root as knowledge/
. That placement is intentional so I can open the repo as an Obsidian vault. Subagents read and write through
src/lib/knowledge.ts
, which path-sandboxes everything to
KNOWLEDGE_ROOT
.
Third, Claude Code hooks live as TS scripts under .claude/hooks/
, not inline in settings.json
.
SessionStart
queries
p0Tasks
,
blockedTasks
, and
staleTasks
, then pipes a markdown summary to stdout.
PreToolUse
(matcher: Task) reads the JSON payload from stdin, extracts
subagent_type
, and writes a role-specific reminder. Keeping hook bodies in TypeScript means they reuse the same Prisma client and view functions the UI uses.
Fourth, the DB is pinned to Neon serverless Postgres, and local dev uses a Neon dev branch — there is no SQLite anywhere. SQLite-local-Postgres-prod looks convenient until column behavior, JSONB indexing, and transaction isolation start drifting between environments and you ship bugs that only surface in production. Applying the "one validation surface" rule to the database, basically.
DATABASE_URL
points at Neon's pooled endpoint;
DIRECT_URL
points at the direct endpoint and is reserved for migrations.
This is the new piece compared to the original write-up. Switching from SQLite to Neon serverless Postgres wasn't cosmetic — it filled four very specific gaps in subagent operations. Honestly, I expected "branching for a one-person stack" to be overkill. Neon's branching turned out to be the single most-used safety device in the whole architecture — that's a sentence I couldn't have written before running this for a few hundred hours.
When a subagent runs schema-touching work (migrations, new columns, index changes), letting it hit the production DB directly is scary. A Neon branch is a fully isolated DB you can spin up in seconds, carrying the production data shape so experiments are realistic.
# Branch off main and hand the agent the branch's DATABASE_URL
neonctl branches create --name preview/agent-add-tags-col --parent main
neonctl connection-string preview/agent-add-tags-col --pooled
# The agent runs the migration on the branch
prisma migrate dev --name add_tags_col
# Re-apply on main if review passes; otherwise drop the branch and move on
neonctl branches delete preview/agent-add-tags-col
The Decision Boundaries doc explicitly forbids direct schema pushes to the prod branch — every migration goes through a preview branch first. Structurally identical to "no direct push to main" in git, and the minimum bar I want when handing schema authority to an AI.
For Lesson 2's Inbox bulk-deletion incident, all I had at the time were manual SQLite snapshots. Neon's Point-in-Time Restore goes back to the second, up to 30 days depending on the plan. You branch from five minutes before the event and copy back just the rows that were deleted.
neonctl branches create \
--name recover/inbox-2026-05-03 \
--parent main \
--timestamp "2026-05-03T03:14:00Z"
When "irreversible mistake" turns into "five-minute rollback," the psychological bar for what you'll let an agent attempt drops noticeably. That's an effect I couldn't have predicted on paper.
Once
handoffs/
and
decisions/
get past a few dozen entries, filename search stops working — "where was that ADR about model selection?" Neon ships pgvector natively, so I embed handoff/ADR text and store the vectors in the same DB.
// src/lib/embeddings.ts
import { prisma } from './db'
import { embed } from './embedder'
export async function searchHandoffs(query: string, k = 5) {
const [{ embedding }] = await embed([query])
// pgvector cosine distance for nearest-neighbor search
return prisma.$queryRaw<
Array<{
taskId: string
slug: string
similarity: number
}>
>`
SELECT "taskId", "slug",
1 - ("embedding" <=> ${embedding}::vector) AS similarity
FROM "HandoffEmbedding"
ORDER BY "embedding" <=> ${embedding}::vector
LIMIT ${k};
`
}
Filename lookup is for known IDs. pgvector is for fuzzy recall — "find me prior work that smells like this." A subagent that calls
searchHandoffs("similar prior decisions")
gets semantically nearby notes without me having to remember the exact slug, and handoffs stop being write-only.
This is directly downstream of Lesson 1's "previously impossible work becoming viable." Neon compute auto-suspends after an idle window, which kills the bill while no agent is running. In practice, nightly QA runs ~2–3 minutes per hour, so the 24/7 footprint stays in the low single-dollar range monthly.
Running a 24-hour organization without worrying about server costs — that was the single biggest win from the Vercel + Neon pair, in my current view.
Subagents live in
.claude/agents/<role>.md
with YAML frontmatter. The
description
field doubles as the Claude Code router, so writing it as "Use when… Do not invoke for…" is critical.
| Group | Agents | Model | Primary responsibilities |
|---|
| Leadership / Routing | engineering-lead / business-director / task-dispatcher | sonnet / sonnet / haiku | Decompose work, route, prioritize |
| Engineering | frontend-engineer / backend-engineer / infra-ops | sonnet / sonnet / haiku | UI / schema-API-CLI / board hygiene + nightly jobs |
| Quality | qa-reviewer / brand-voice-reviewer / anti-ai-slop-reviewer | sonnet / haiku / haiku | AC verification / brand alignment / AI-slop detection |
| Content / Strategy / Legal | content-director / legal-first-pass / morning-standup-writer | sonnet / sonnet / haiku | Long-form structure / contract first-pass / morning brief |
The base routing flow is short:
operator note → task-dispatcher → specialist
↘ engineering-lead (engineering, complex)
↘ business-director (strategy)
engineer finishes → qa-reviewer → Done
↘ back to engineer (FAIL)
content draft → content-director → brand-voice-reviewer
↘ anti-ai-slop-reviewer
contract → legal-first-pass → operator (always)
Model selection is simple: roles that exercise judgment over multi-file context (engineering, content, QA, legal) run on Sonnet. Rule-following / detection roles where the prompt does most of the thinking (slop, voice, dispatcher, infra hygiene, morning brief) run on Haiku. Opus is intentionally not in the roster. Strategic calls are picked up by me or escalated as ADRs. That keeps cost and ownership clean.
Here's a slightly simplified version of
backend-engineer
. Writing the description as
a router switch is the most important part. Vague descriptions cause task-dispatcher to misroute work.
---
name: backend-engineer
description: >
Use when the task touches src/lib/, prisma/schema.prisma, server actions,
API routes under src/app/api/, scripts/jobs/, or scripts/cli/. Do not
invoke for UI changes (use frontend-engineer) or stale-board hygiene
(use infra-ops).
model: sonnet
tools: [Read, Write, Edit, Bash, Glob, Grep]
---
# Backend Engineer
## Scope
- Prisma schema and migrations (always on a Neon preview branch first)
- Validation helpers in src/lib/tasks.ts
- Server actions and API routes
- Job scripts in scripts/jobs/
## Workflow
1. Read the task and acceptanceCriteria from the board
2. Implement minimum viable change; do not refactor unrelated code
3. Add a regression test or CLI invocation that proves the change
4. Move task to Review with a one-line summary in handoffNote
## Don'ts
- Never run prisma migrate reset
- Never push schema directly to the Neon prod branch (use a preview branch)
- Never add a dependency without an ADR
- Never edit .claude/agents/\* — escalate to operator
The "Do not invoke for…" tail of the description is the part most people skip, and it's the part that actually pays the rent. Codifying what an agent must NOT do is what makes role boundaries crisp — exactly the same lesson I beat into the investment team during DD standardization.
The board core is a single Prisma
Task
table living in Neon Postgres. Enums could be promoted to Postgres native enums, but I keep them as
string
for portability with local mocks and tests.
auditTrail
is a Postgres-native JSONB column now — no more "stringify and parse on every read" the way I had to under SQLite. Partial-match queries like
auditTrail @> '[{"event":"deleted"}]'::jsonb
become available out of the box.
// src/lib/types.ts
export const STATUSES = [
'Inbox',
'Unassigned',
'InProgress',
'Blocked',
'Review',
'Done',
'Archived',
] as const
export const PRIORITIES = ['P0', 'P1', 'P2', 'P3'] as const
export const TEAMS = ['engineering', 'content', 'business', 'infra', 'human'] as const
export type AuditEntry = {
ts: string
actor: string // "agent:backend-engineer" or "human:operator"
event: string // e.g. "status:InProgress->Review"
detail?: string
}
The Neon-specific bits show up in the Prisma schema:
// prisma/schema.prisma — Neon-specific bits
generator client {
provider = "prisma-client-js"
previewFeatures = ["postgresqlExtensions"]
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL") // Neon pooled
directUrl = env("DIRECT_URL") // Neon direct (for migrate)
extensions = [pgvector]
}
model Task {
id String @id @default(cuid())
status String
priority String
team String
auditTrail Json // Postgres JSONB — supports @> partial match
// ...
}
model HandoffEmbedding {
taskId String @id
slug String
embedding Unsupported("vector(1536)")?
createdAt DateTime @default(now())
}
The state transitions are easier to read as a table. Note that Review→Done flags a missing
handoffNote
as a
warning, not an error. Hard-rejecting it would just make agents stuff in empty strings — surfacing as a warning encourages real handoff notes without blocking the flow.
| From → To | Required | Audit event | Side effect |
|---|
| new → Inbox | title, description, createdBy | created | auditTrail initialized |
| InProgress → Blocked | blockerReason | status:InProgress->Blocked | — |
| InProgress → Review | acceptanceCriteria | status:InProgress->Review | qa-reviewer auto-picks up |
| Review → Done | handoffNote (recommended) | status:Review->Done | completedAt set |
| any → Archived | — | archived | excluded from listTasks |
Deletion is not exposed via UI or CLI. This single rule has prevented several near-incidents. If real deletion is ever needed, I open
prisma studio
manually.
knowledge/
lives at the repo root and opens as an Obsidian vault as-is. Subagents
never chat with each other in real time. They write files instead.
knowledge/
├── inbox/ # brain dumps, nightly snapshots, morning briefs
├── projects/ # per-initiative briefs
├── ideas/ # not-yet-projects
├── resources/ # reference material
├── context/ # philosophy, identity, voice, strategy, boundaries
├── handoffs/ # <task-id>-<slug>.md handoff notes
├── decisions/ # numbered ADRs
└── playbooks/ # nightly-qa and other repeatables
context/
and
handoffs/
are the two folders that earn their keep.
context/
holds philosophy, professional-identity, visual-design-language, product-strategy, and decision-boundaries — every agent gets that as ambient "what is ZYL0 Lab" memory.
Handoff filenames follow
<task-id>-<slug>.md
, so
pnpm task show <id>
and
ls knowledge/handoffs/<id>-*.md
work as bidirectional lookups.
For the cases where filename lookup isn't enough — "find me a similar prior decision" — agents call searchHandoffs
against the pgvector store on Neon, exactly the win described in reason 3 above. Filename and semantic recall sitting in the same DB has been more useful than I expected.
Designing AWS IoT Core async messaging years ago left me with a strong intuition: real-time sync is fragile, async queues plus durable logs are robust. Subagent operations are the same — writing handoffs to files instead of conversations turns debugging from impossible to tractable.
Of everything I built for this org,
knowledge/context/decision-boundaries.md
was the highest-leverage single document. It draws lines in three regions.
Agents may decide on their own
- File-level refactors within the assigned task
- Adding tests for code already being changed
- Reorganizing notes within an existing folder
- Reassigning to a more appropriate sub-agent (must record in audit)
- Marking another agent's task
Review
after independent verification
Agents must escalate to the operator
- Any change to
prisma/schema.prisma
requiring a migration - Adding dependencies to
package.json
- Changes to
.claude/settings.json
, .claude/agents/*
, .claude/skills/*
, or CLAUDE.md
- Anything touching cloud or external systems
- Any decision that warrants an ADR
- Transition to
Blocked
on operator input
Hard stops (never without explicit operator confirmation)
git push --force
prisma migrate reset
rm -rf
pnpm prune
- Archiving a task another agent is working on
- Editing existing entries under
knowledge/decisions/
(only append new ADRs) - Direct schema push to the Neon prod branch (must go via a preview branch)
The escalation mechanism is encoded too. The agent moves the task to
Unassigned
and fills in the fields:
assigneeType
= human
assigneeId
= operator
- Sets priority
- Writes the question into
description
or handoffNote
My
/board/needs-attention
view picks it up automatically.
This is the part I most wanted to write. After ~500 hours of direct operator time and roughly 1,000 hours of cumulative agent runtime, here's what I now consider truly important.
Overnight QA, knowledge/ cleanup, the stale-check job — these are jobs that don't make economic sense for a solo player. They aren't worth the time, so usually nobody does them. But with autonomous subagents, you can run them 24/7 at near-zero marginal cost. The result: "Silicon-Valley-grade quality processes" become attainable at the scale of a single-person operation, possibly for the first time. That's what hit me hardest. The real value of an organized AI setup, in my current view, isn't time saved — it's "work that was previously impossible becoming economically viable." Neon's suspend-on-idle compute and Vercel's serverless billing line up directly with that thesis: when the bill stops while no agent is running, a 24/7 shift becomes affordable for one person.
A human new hire would sense "I probably shouldn't delete the Inbox unilaterally." A subagent senses no such thing. If you didn't write "do not delete," there is a real chance it will delete. This isn't a metaphor — it actually happened in my knowledge/ vault. One agent declared "I'll tidy up" and bulk-deleted unprocessed Inbox notes.
The lesson: every judgment criterion has to be written down explicitly. The board now exposes only
Archived
, not
delete
.
handoffs/
is explicitly listed under "do not delete" in
decision-boundaries.md
. It was the same during the DD standardization — every place I cut corners on the assumption "this is obvious" eventually produced an incident.
One footnote: after moving to Neon, PITR turned "irreversible incident" into "five-minute rollback." Written rules remain the first line of defense; Neon's restore is the second line — a two-layer setup that didn't exist on SQLite.
This is the scariest lesson. Subagent organizations break without errors or warnings. A corrupted config file? "Write complete, moving on." A clogged task queue? "In progress" indefinitely.
A human new hire would escalate "this message hasn't reached me." AI doesn't. So "the agent reported it's running" is never enough. Every morning,
morning-standup-writer
produces a brief at
knowledge/inbox/morning-brief-latest.md
containing the overnight summary, today's focus, and an editor's note. Three minutes of reading and I know whether the org is healthy. Observability is, I'd argue, a non-negotiable requirement for subagent operations.
Sharing the most frequent traps from 500+ hours of direct ops.
Trap 1: Vague descriptions clog the router. "Use when engineering tasks" is too broad — task-dispatcher routes UI, schema, and infra hygiene all to backend-engineer. Workaround: write the description as a symmetric "Use when X. Do not invoke for Y." The Y side is what actually sharpens routing accuracy.
Trap 2: Validation logic drifts. When UI server actions, REST routes, and CLI each carry their own validation, the specs diverge. Workaround: keep
validateTaskCreate
/
validateTaskUpdate
as the only exports from
src/lib/tasks.ts
and route every entry path through them. This works precisely because the CLI shares the same Prisma client.
Trap 3: The board rots. Tasks completed but never transitioned out of
InProgress
accumulate — dozens within days. Workaround: a nightly
scripts/jobs/stale-check.ts
flags non-Done / non-Archived tasks whose
updatedAt
is over 72 hours old as
stale
. Crucially,
it never auto-archives. infra-ops surfaces "this looks stale" to the operator; the call stays human.
Trap 4: AI-flavored prose creeps in. With content-director alone, "as you can see" phrasing and em-dash padding inevitably leak through. The workaround is keeping anti-ai-slop-reviewer at the final check stage, with a list of phrases I never use, forcing a rewrite on any hit.
Trap 5: Connection management on Vercel + Neon. Vercel serverless functions open a fresh connection per invocation, which hits Neon's connection limit fast. The workaround is to point
DATABASE_URL
at Neon's
pooled endpoint with
?pgbouncer=true&connection_limit=1
, and
DIRECT_URL
at the direct endpoint reserved for
prisma migrate
. Routes that run in edge runtime get switched to
@neondatabase/serverless
(the HTTP/WebSocket driver). That three-lane setup has been the most stable so far. Prisma Data Proxy is another option, but it conflicts with the "CLI and UI share the same Prisma client" principle, so I haven't adopted it.
After 500 hours of direct operations and roughly 1,000 hours of cumulative runtime, the conclusion is simpler than I expected.
These four are nearly identical to the methodology I used when standardizing the investment team's DD process. There's nothing AI-specific required as a principle — the answers human organizations have refined over a long arc still apply, with AI's distinct strengths layered on top (24/7 uptime, cost optimization, parallelism). That's the view from where I currently stand.
Arguing about which model is strongest is a surface-level game. The real edge comes from how you run it. Whether your stack is Claude, Gemini, or GPT, a Prisma table plus a markdown vault as the shared substrate carries over. And the moment that Prisma table sits on Neon, four pieces of gear show up at once: branching, PITR, pgvector, and suspend-on-idle. Running 12 autonomous subagents against a real production database without flinching is what that combination buys you.
- Idea 1: A data-updated follow-up — Revisit the thesis with fresh numbers and separate what strengthened from what broke.
- Idea 2: A practical template edition — Turn the article into a checklist readers can reuse for investing, pricing, or technical operations.
- Idea 3: The bear-case test — Define the conditions that would invalidate this view and map the indicators to watch next.
The factual and numerical assumptions in this article are anchored to primary or public materials that readers can revisit during AdSense review and future updates.
This article is for informational purposes only and does not constitute investment advice or a recommendation of any specific stock, service, or contract structure. The author may hold positions or interests related to companies or services mentioned. Generative AI was used for parts of research, translation, and proofreading, with final review by ZYL0. See the disclaimer for details.