Claude Code 2026年最新アップデート総まとめ|1Mコンテキスト・Skill・Hook・Subagent・MCP・Plan modeを実戦投入する
バージョン注記: 2026年5月時点のClaude Code公式ドキュメントと、ZYL0 Blogのローカル運用を前提にしています。モデル名、CLIオプション、設定ファイルの仕様は変わる可能性があるため、導入時は公式Docsを確認してください。
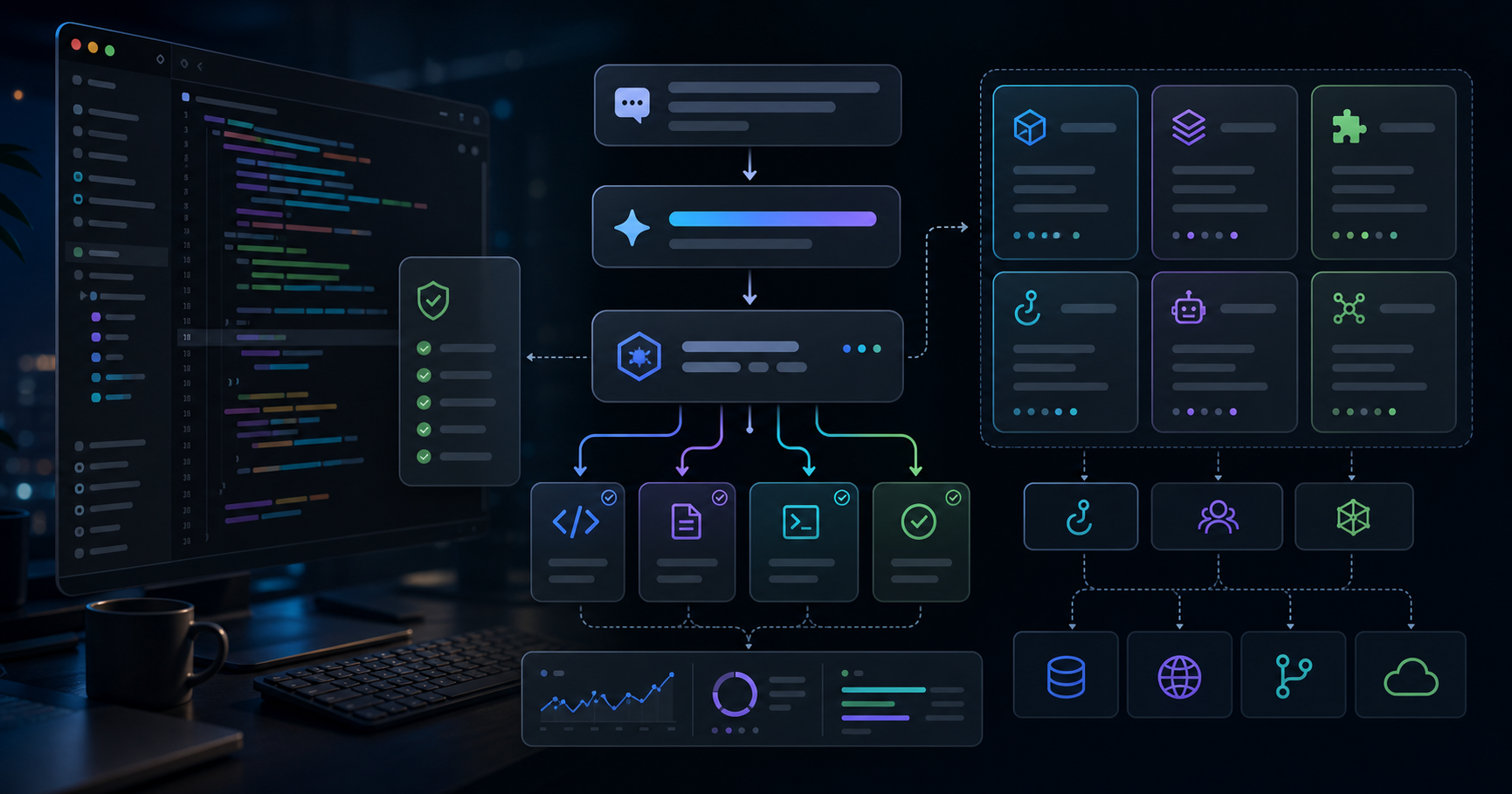
Claude Codeは、単なる「コードを書いてくれるCLI」から、開発作業のOSに近いものへ変わりつつあります。私が特に大きいと感じているのは、1Mコンテキスト、Skill、Hook、Subagent、MCP、Plan modeの6つです。単体で見ると便利機能ですが、組み合わせると開発の進め方そのものが変わります。
この記事では、各機能をニュース紹介ではなく「どの順番で実務に入れるべきか」という観点で整理します。CVCの仕事と個人開発を並行している身としては、派手な機能よりも、手戻りを減らし、同じ説明を繰り返さず、危険操作を止められる設計の方が価値があります。
| 機能 | 実務での使いどころ | 最初に見るリスク |
|---|
| 1Mコンテキスト | 大きなrepoや長い差分を1セッションで読む | コストと遅延 |
| Skill | プロジェクト固有の作法を再利用する | descriptionが曖昧だと発火しない |
| Hook | 実行前後に安全確認を入れる | 厳しすぎると開発を止める |
| Subagent | 調査、レビュー、実装を分担する | 責務が曖昧だと重複する |
| MCP | 外部データや社内ナレッジへ接続する | 権限と情報漏洩 |
| Plan mode | 読み取り専用で計画を固める | 小さい作業では重く感じる |

1Mコンテキストの価値は、何でも長く読めることではありません。大きなrepo、長いログ、過去の議論、設計メモを一度に持って、判断の分断を減らせることです。
ただし、常用する必要はありません。私の運用では次のように分けます。
| 作業 | 推奨コンテキスト | 理由 |
|---|
| 小さな文言修正 | 通常モデル | 速さを優先 |
| 1〜3ファイルの実装 | 通常モデル | grepと型で足りる |
| 複数ページのUI改修 | 広めのコンテキスト | 依存関係を見たい |
| 大規模リファクタ | 1Mコンテキスト | 分割判断のズレを減らす |
| 障害調査 | 1Mコンテキスト | ログ、差分、設定を同時に読む |
1Mは「高級な常用モード」ではなく、「分割すると危ない作業の保険」として使う方が費用対効果が高いと見ています。
Skillは、同じ説明を何度も繰り返さないための仕組みです。ZYL0 Blogなら、frontmatter、日英ブロック、参考資料、免責、承認済みタグなどをSkillに入れます。
私が重要だと思うのは、Skillを「文章生成テンプレ」ではなく「品質基準」として扱うことです。
description: >
Use when the user asks to create, revise, or audit a ZYL0 Blog article.
Require bilingual sections, approved tags, references, disclaimer,
and an AdSense quality gate before publishing.
descriptionが曖昧だとSkillは呼ばれません。逆に、ユーザーが実際に言う語を入れると安定します。「Claude Code」「MCP」「AdSense」「参考資料」「ブログ品質」のような語は、抽象語よりも強いトリガーになります。
Hookは便利ですが、使いすぎると開発体験を壊します。私の基準は、判断を代替させるのではなく、事故だけ止めることです。
| Hook対象 | 入れる価値が高い例 | 避けたい例 |
|---|
| PreToolUse | 破壊的コマンド、外部送信、機密ファイル編集 | すべての編集を止める |
| PostToolUse | build失敗、型エラー、生成ファイル肥大化 | 毎回長いレビューを走らせる |
| Stop | 最終監査、未完了タスク確認 | 小さな質問にも強制チェック |
半導体プロセス開発で学んだ感覚に近いのですが、歩留まりを上げるには検査を増やすだけでは足りません。検査が多すぎるとラインが止まる。Hookも同じで、止める場所を絞る必要があります。
Subagentは、同じ会話に全部を詰め込まないために使います。記事制作なら、投資視点、技術視点、読者ニーズ視点を分けて調べる。開発なら、探索、実装、レビューを分ける。
| 使い方 | 効く理由 |
|---|
| 調査を分ける | メイン文脈を汚さずに情報を集められる |
| レビューを分ける | 実装者とは別の視点で欠陥を探せる |
| 長い比較を分ける | 1つの会話で論点が混ざりにくい |
ただし、Subagentに文体ルールや記事フォーマットを持たせすぎると、Skillと責務が重なります。Subagentは「調べる・見る」、Skillは「どう書く・どう出す」と分けるのが扱いやすいです。
MCPは「AIに道具を持たせる」仕組みですが、重要なのは接続先を増やすことではありません。外部状態を、必要なときだけ正しく取りに行けることです。
私が優先する接続先は次です。
| 接続先 | 価値 | 注意点 |
|---|
| GitHub | PR、Issue、差分レビュー | 権限を絞る |
| Google Drive / Notion | 過去メモ、企画、提案書 | 個人情報の扱い |
| Figma | UI文脈、デザイン確認 | 画像だけで判断しない |
| Vercel | deploy、logs、preview確認 | 本番操作は慎重に |
MCPは強力ですが、情報漏洩と誤操作のリスクもあります。最初は読み取り中心で始め、書き込み系はHookや明示確認と組み合わせるのが現実的です。
Plan modeは、小さな修正では回りくどく感じることがあります。ただ、複数ファイル、仕様変更、AdSense再審査のような品質改修ではかなり効きます。読み取り専用で環境を確認し、実装前に成功条件を固められるからです。
今回のブログ改修でも、先に全記事の本文量、参考資料、免責、Skill差分を見たことで、単純な加筆では足りない箇所を切り分けられました。計画がないまま触ると、記事24や20のようなコード例を含む記事で、正規表現が誤爆するリスクも上がります。
- まず公式Docsとリリースノートで、Skill、Hook、MCP、Subagentの責務が変わっていないかを見る。
- 次に、自分のrepoで
npm run build
が通るか、既存Skillが期待通り発火するかを確認する。 - 最後に、新機能を入れる前に「既存運用のどの手戻りを減らすのか」を1文で書く。
- 案1:Claude Code Skillの監査テンプレート — description、出力形式、参考資料、免責、検証コマンドをまとめた実務チェックリスト。
- 案2:Subagentでブログリサーチを並列分業する型 — 投資、技術、読者ニーズを分けて調査し、1本の記事に統合する手順。
- 案3:MCPで社内ナレッジを30分で接続する — DDメモ、過去提案、ポートフォリオ情報をClaude Codeに接続する実装ルート。
本文の技術前提と運用判断は、読者が後から確認できる公式資料を優先して見直しています。
本記事は情報提供を目的としたものであり、特定の銘柄、サービス、契約条件の推奨や投資助言ではありません。執筆者は記事内で触れた銘柄やサービスにポジションまたは利害関係を持つ可能性があります。調査、翻訳、校正の一部に生成AIを利用していますが、最終的な内容はZYL0が確認しています。詳細は免責事項をご確認ください。
Claude Code 2026 Feature Roundup: Putting 1M Context, Skills, Hooks, Subagents, MCP, and Plan Mode to Real Work
Version note: This article reflects Claude Code documentation and the ZYL0 Blog local workflow as of May 2026. Model names, CLI options, and configuration behavior may change, so check official documentation before implementation.
Claude Code is moving from "a CLI that writes code" toward something closer to an operating layer for development work. The six features that matter most in my workflow are 1M context, Skills, hooks, subagents, MCP, and Plan mode. Each is useful alone, but the real leverage appears when they work together.
This article is not a news roundup. It is an implementation order: what to adopt first, what to delay, and what risk to watch before adding each feature.
| Feature | Practical use | First risk to watch |
|---|
| 1M context | Read large repos and long diffs in one session | Cost and latency |
| Skills | Reuse project-specific operating rules | Vague descriptions fail to trigger |
| Hooks | Add safety checks before and after actions | Over-strict hooks block work |
| Subagents | Split research, review, and implementation | Unclear ownership creates duplication |
| MCP | Connect external data and internal knowledge | Permissions and leakage |
| Plan mode | Lock scope before mutation | Feels heavy for tiny changes |
The value of 1M context is not that it can read a lot for its own sake. The value is that it reduces broken judgment across large codebases, long logs, design notes, and past decisions.
I do not treat it as the default mode.
| Work type | Suggested context | Why |
|---|
| Small copy edit | Normal model | Speed matters more |
| One to three files | Normal model | Search and types are enough |
| Multi-page UI change | Wider context | Dependencies matter |
| Large refactor | 1M context | Avoid split-session drift |
| Incident investigation | 1M context | Logs, config, and diffs need to sit together |
The practical rule: use 1M when splitting the work would introduce risk.
Skills are for rules you do not want to repeat. For ZYL0 Blog, that means frontmatter, bilingual sections, references, disclaimers, and approved tags.
The description needs routing language:
description: >
Use when the user asks to create, revise, or audit a ZYL0 Blog article.
Require bilingual sections, approved tags, references, disclaimer,
and an AdSense quality gate before publishing.
Concrete trigger phrases beat elegant abstractions. "Claude Code," "MCP," "AdSense," "references," and "blog quality" are stronger routing signals than "technical content."
Hooks are useful, but too many checks can damage the workflow. My rule is simple: hooks should stop accidents, not make editorial or architectural decisions.
| Hook target | High-value use | Avoid |
|---|
| PreToolUse | destructive commands, external writes, sensitive files | blocking every edit |
| PostToolUse | failed builds, type errors, oversized generated files | long reviews after every step |
| Stop | final audit, unresolved tasks | forcing ceremony for small questions |
This resembles process engineering. More inspection does not automatically improve yield; the inspection has to sit at the right failure point.
Subagents help keep the main conversation clean. In article work, I use them for investment research, technical research, and reader-needs research. In development, they fit exploration, implementation, and review.
| Pattern | Why it helps |
|---|
| Separate research | Gather facts without polluting the main thread |
| Separate review | Find defects from a different angle |
| Separate comparisons | Avoid mixing too many criteria in one conversation |
Keep format rules in Skills. Keep investigation in subagents.
MCP is powerful because it lets the model fetch external state when needed. The goal is not to connect everything. The goal is to connect the few systems that materially reduce stale context.
| Connection | Value | Caution |
|---|
| GitHub | PRs, issues, diffs | Scope permissions |
| Google Drive / Notion | old notes, proposals, briefs | handle private data carefully |
| Figma | UI and design context | verify beyond screenshots |
| Vercel | deploys, logs, previews | be careful with production actions |
Start read-only where possible. Add write actions only when permissions and review gates are clear.
Plan mode can feel heavy for tiny edits. It pays off when the work touches many files, changes policy, or needs quality criteria before mutation. AdSense remediation is a good example: you need to inspect content depth, references, disclaimers, and Skill rules before changing anything.
It also prevents a specific failure mode: using a broad rewrite before understanding the structure. Articles with code examples require more careful parsing than ordinary Markdown.
- Start with official docs and release notes to see whether Skill, Hook, MCP, or subagent responsibilities changed.
- Then verify your own repo still builds and existing Skills still trigger in the expected situations.
- Before adopting a new feature, write one sentence explaining which existing source of rework it removes.
A practical way to sequence adoption is to move from the least invasive change to the most. The 1M context window and Plan Mode change nothing in your repository, so they are safe to try first on a real task and keep only if they measurably reduce rework. Skills and Hooks come next, because they encode standing rules that every future session inherits; they are worth the setup cost only once a workflow has stabilized enough that the rules will not churn weekly. Subagents and MCP connections come last, since they add moving parts, permissions, and external state that you then have to maintain and secure. The failure mode to avoid is enabling all six features at once and losing the ability to attribute an improvement, or a regression, to any single one. Adopt one feature, run it against your own work for a week, and only then decide whether it earns a permanent place in your setup.
- Idea 1: A Claude Code Skill audit template — A practical checklist for descriptions, output format, references, disclaimers, and verification commands.
- Idea 2: Parallel blog research with subagents — Split investment, technical, and reader-needs research before merging one final article.
- Idea 3: Connecting internal knowledge over MCP — Wire diligence notes, old proposals, and portfolio context into Claude Code in 30 minutes.
- 10 Claude Code Skill Design Patterns: Descriptions and Templates That Trigger Reliably — Ten Skill design patterns for Claude Code: how to write descriptions that trigger reliably, split Skills by audience, …
- The Shortest Path to Connecting Internal Knowledge over MCP: Wiring DD Memos, Portfolio Data, and Old Proposals into Claude Code in 30 Minutes — A 30-minute build log: a minimal MCP server that lets Claude Code search CVC DD memos, portfolio data, and past propos…
- Parallel Blog Research with Subagents: Fan Out Investment, Technical, and Reader-Need Axes, Then Merge Into One Draft — A hands-on build log: split one blog post's research into investment, technical, and reader-need axes, run them as par…
The technical assumptions and operating recommendations in this article are grounded in official materials readers can revisit.
This article is for informational purposes only and does not constitute investment advice or a recommendation of any specific stock, service, or contract structure. The author may hold positions or interests related to companies or services mentioned. Generative AI was used for parts of research, translation, and proofreading, with final review by ZYL0. See the disclaimer for details.